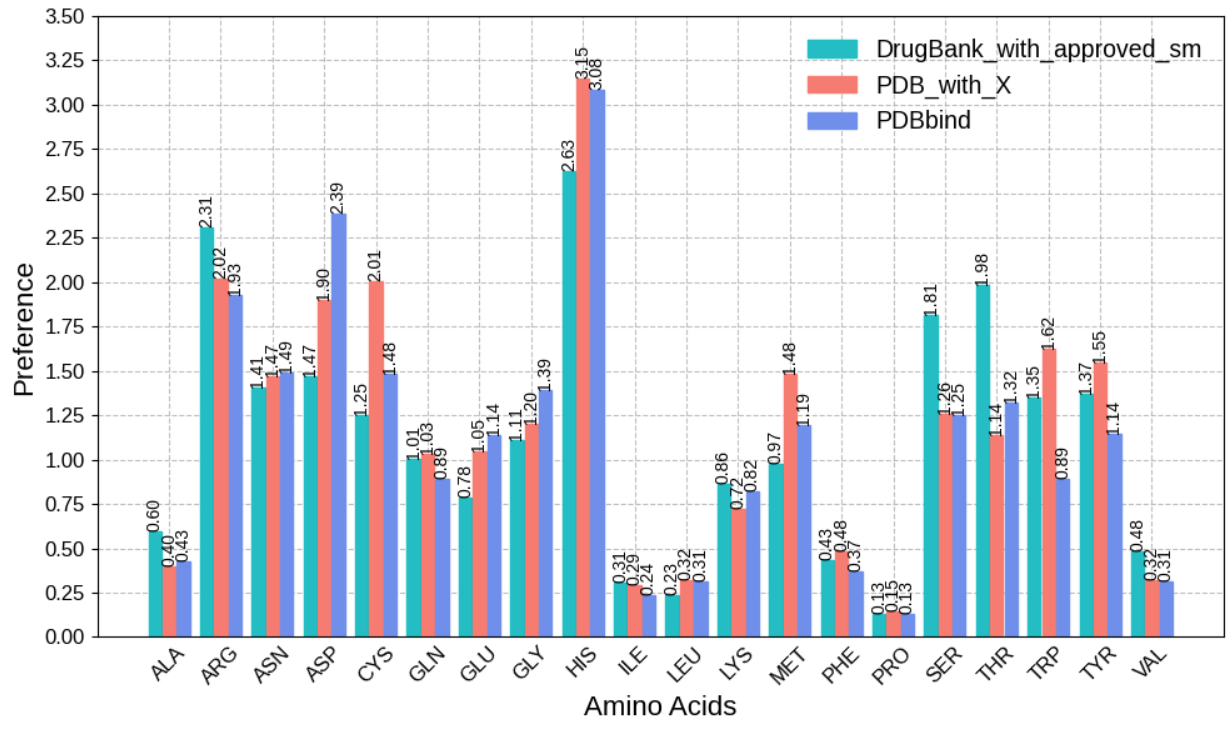
Python 图表
分组柱状图
- #统计每个数据库形成氢键的氨基酸偏好性,分组柱状图
- dataset_names = ["DrugBank_with_approved_sm", "PDB_with_X", "PDBbind"]
- colors = ['#00bfc4', '#f9766e', '#6495ED']
- width_multi = [1,0,-1]
- plt.figure(figsize=(10,6))
- plt.rcParams['font.sans-serif']=["Liberation Sans"]
- for i in range(3):
- name = dataset_names[i]
- data = vars()["hbonds_"+name]
- res_fre = occupancy_divide_base_fre(data, base_fre, name).to_dict()
- triple_20_AA = ["GLY", "ALA", "SER", "PRO", "VAL", "THR", "CYS", "ILE", "LEU","ASN", "ASP", "GLN", "LYS", "GLU", "MET", "HIS", "PHE","ARG", "TYR", "TRP"]
- for res in triple_20_AA:
- if res not in res_fre.keys():
- res_fre[res] = 0.0
- res_fre=[(k,res_fre[k]) for k in sorted(res_fre.keys())]
- x = np.arange(0,len(res_fre)*8,8)
- width=2
- x1 = x-width_multi[i]*width*1.1
- y1 = [i[1] for i in res_fre]
- # 绘制分组柱状图
- plt.bar(x1,y1,width=width,label=name,color=colors[i],edgecolor=colors[i], zorder=2)
- for a,b in zip(x1,y1): #柱子上的数字显示
- plt.text(a,b,'%.2f'%b,ha='center',va='bottom',fontsize=10, rotation=90)
- # 添加x,y轴名称、图例和网格线
- plt.xlabel('Amino Acids',fontsize=16)
- plt.ylabel('Preference',fontsize=16)
- plt.legend(frameon=False,loc=1,fontsize=14)
- plt.grid(ls='--',alpha=0.8)
- # 修改x刻度标签
- x_lable = [i[0] for i in res_fre]
- plt.xticks(x,x_lable,rotation=45,fontsize=12)
- plt.yticks(np.arange(0,3.75,0.25),fontsize=12)
- plt.tick_params(axis='x',length=0)
- plt.tight_layout()
- plt.savefig("./graph/hbonds_three_subsets_aa_frequency.png",dpi=600)
- plt.show()
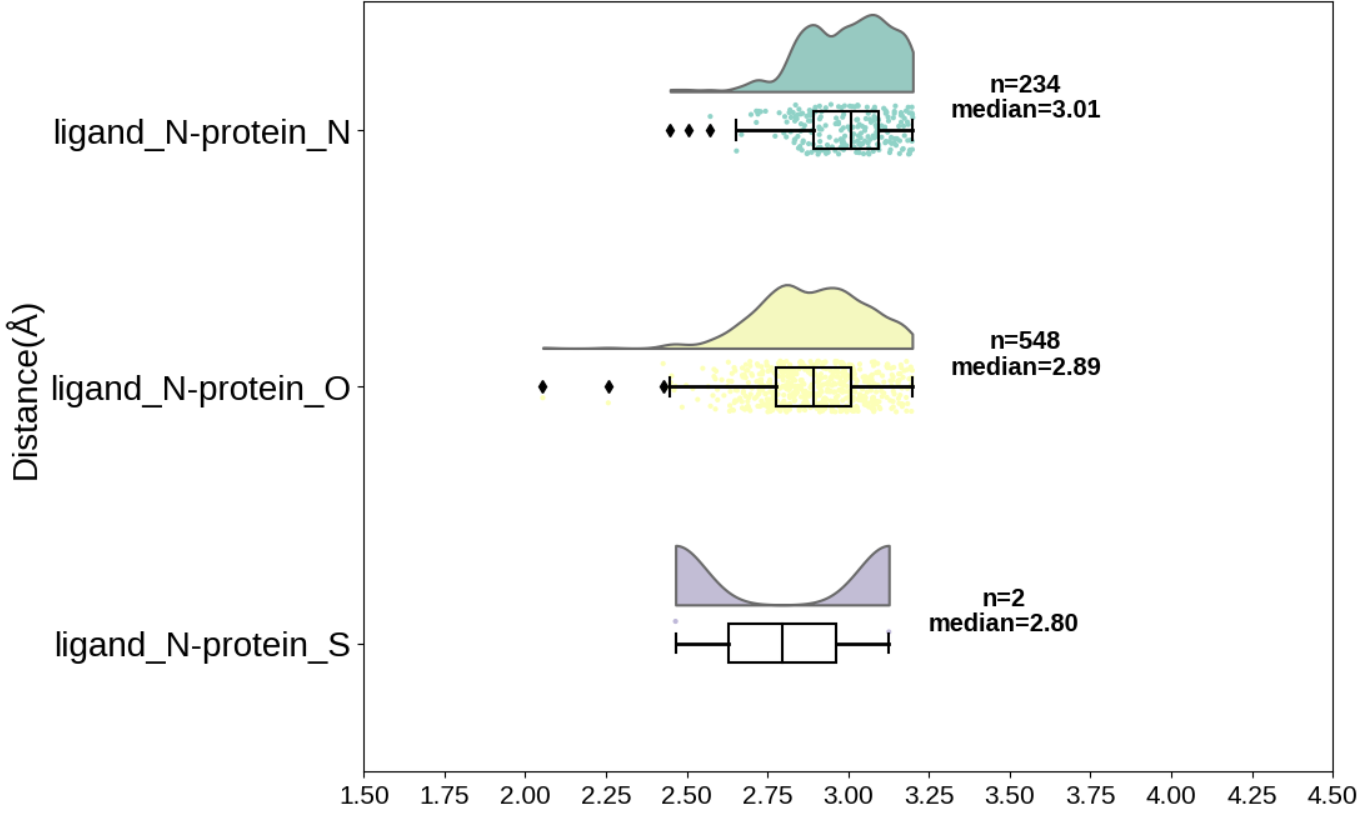
半小提琴与箱线图
- #与配体N、O形成氢键的距离分布,,半小提琴图与箱线图
- elem_in_ligands = ["N", "O"]
- for elem in elem_in_ligands:
- X_O_distance = vars()["elem_" + elem][vars()["elem_" + elem].loc[:,"residue atom elem"]=="O"]["distance"]
- X_N_distance = vars()["elem_" + elem][vars()["elem_" + elem].loc[:,"residue atom elem"]=="N"]["distance"]
- X_S_distance = vars()["elem_" + elem][vars()["elem_" + elem].loc[:,"residue atom elem"]=="S"]["distance"]
- X_N_O_S_distance = pd.concat((X_N_distance,X_O_distance,X_S_distance), axis=1, ignore_index=True)
- X_N_O_S_distance.columns = ["ligand_"+elem+"-protein_N","ligand_"+elem+"-protein_O","ligand_"+elem+"-protein_S"]
- print(X_N_O_S_distance.head())
- ort="h"
- plt.rcParams['font.sans-serif']=["Liberation Sans"]
- ax = plt.figure(figsize=(10, 8)).add_subplot()
- ax=pt.half_violinplot(data=X_N_O_S_distance, palette="Set3", bw=.2, cut=0.,
- scale="area", width=.6, inner=None, orient=ort)
- ax=sns.stripplot(data=X_N_O_S_distance, palette="Set3", edgecolor="white",
- size=3, jitter=1, zorder=0, orient=ort, )
- ax=sns.boxplot(data=X_N_O_S_distance, color="black", width=.15, zorder=10,
- showcaps=True, boxprops={'facecolor':'none',"zorder":10},
- showfliers=True, whiskerprops={'linewidth':2,"zorder":10},
- saturation=1, orient=ort)
- ax.set_ylabel("Distance(Å)",fontsize=20)
- #ax.set_ylim([1.25,5.75])
- plt.yticks(fontsize=20)
- plt.xticks(np.arange(1.5,4.75,0.25),fontsize=15)
- # Calculate number of obs per group & median to position labels
- medians = np.around(X_N_O_S_distance.median().values,2)
- maxes = np.around(X_N_O_S_distance.max().values,2)
- nobs = ["n="+str(len(X_N_distance)), "n="+str(len(X_O_distance)), "n="+str(len(X_S_distance))]
- # Add text to the figure
- pos = range(len(nobs))
- for tick, label in zip(pos, ax.get_xticklabels()):
- ax.text(maxes[tick] + 0.35, pos[tick]-0.15, nobs[tick], horizontalalignment='center',size='x-large', color='k', weight='semibold')
- ax.text(maxes[tick] + 0.35, pos[tick]-0.05, "median=%.2f"%medians[tick], horizontalalignment='center',size='x-large', color='k', weight='semibold')
- plt.savefig("hbonds_ligand_"+elem+'protein-N_O_S_distance_distribution.png',dpi=600,bbox_inches = 'tight')
- plt.show()
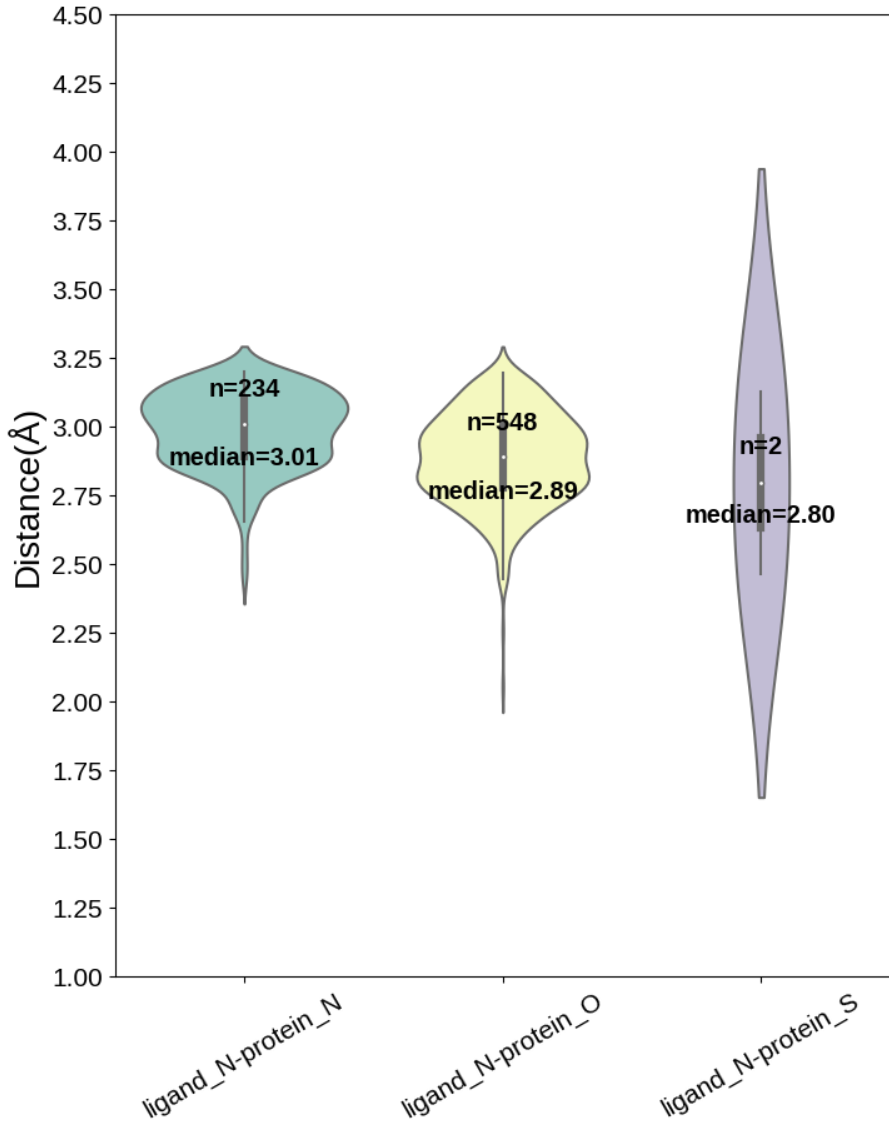
小提琴图
- #与CL、BR、I形成卤键的距离分布,小提琴图
- elem_in_ligands = ["N", "O"]
- for elem in elem_in_ligands:
- X_O_distance = vars()["elem_" + elem][vars()["elem_" + elem].loc[:,"residue atom elem"]=="O"]["distance"]
- X_N_distance = vars()["elem_" + elem][vars()["elem_" + elem].loc[:,"residue atom elem"]=="N"]["distance"]
- X_S_distance = vars()["elem_" + elem][vars()["elem_" + elem].loc[:,"residue atom elem"]=="S"]["distance"]
- X_N_O_S_distance = pd.concat((X_N_distance,X_O_distance,X_S_distance), axis=1, ignore_index=True)
- X_N_O_S_distance.columns = ["ligand_"+elem+"-protein_N","ligand_"+elem+"-protein_O","ligand_"+elem+"-protein_S"]
- print(X_N_O_S_distance.head())
- plt.rcParams['font.sans-serif']=["Liberation Sans"]
- ax = plt.figure(figsize=(8, 10)).add_subplot()
- sns.violinplot(data=X_N_O_S_distance,palette="Set3")
- ax.set_ylabel("Distance(Å)",fontsize=20)
- #ax.set_ylim([1.25,5.75])
- plt.xticks(fontsize=15,rotation=30)
- plt.yticks(np.arange(1,4.75,0.25),fontsize=15)
- # Calculate number of obs per group & median to position labels
- medians = np.around(X_N_O_S_distance.median().values,2)
- nobs = ["n="+str(len(X_N_distance)), "n="+str(len(X_O_distance)), "n="+str(len(X_S_distance))]
- # Add text to the figure
- pos = range(len(nobs))
- for tick, label in zip(pos, ax.get_xticklabels()):
- ax.text(pos[tick], medians[tick] + 0.1, nobs[tick], horizontalalignment='center',size='x-large', color='k', weight='semibold')
- ax.text(pos[tick], medians[tick] - 0.15, "median=%.2f"%medians[tick], horizontalalignment='center',size='x-large', color='k', weight='semibold')
- #plt.savefig(elem+'-N_O_S_distance_distribution_0.0_140.png',dpi=600)
- plt.show()
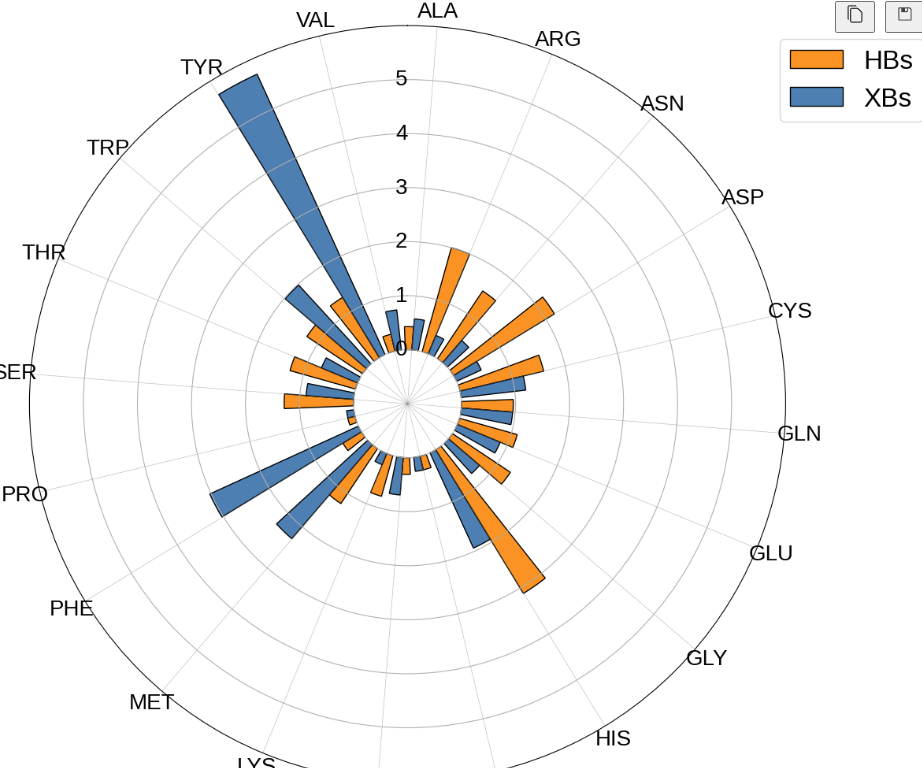
径向柱图
- #径向柱图, halogen_bond (x-y and x-pi) and hbonds aa_frequency
- import colorsys
- import numpy as np
- from matplotlib import cm,colors
- from matplotlib.pyplot import figure,show,rc
- mydata = pd.concat([pd.DataFrame(hbonds_res_fre), pd.DataFrame(xbonds_res_fre)], axis=1)
- mydata.columns = ["HBs", "XBs"]
- #按列求百分比
- plt.rcParams['font.sans-serif']=["Liberation Sans"]
- plt.rcParams["patch.force_edgecolor"]=True
- n_row = mydata.shape[0]
- n_col = mydata.shape[1]
- angle = np.arange(0,2*np.pi,2*np.pi/n_row)
- #cmap = cm.get_cmap("Reds", n_col)
- #color = [colors.rgb2hex(cmap(i)[:3]) for i in range(cmap.N)]
- radius1 = np.array(mydata.HBs)
- radius2 = np.array(mydata.XBs)
- fig = figure(figsize=(12,12))
- ax = fig.add_axes([0.1,0.1,0.8,0.8], polar=True)
- ax.set_theta_offset(np.pi/2)
- ax.set_theta_direction(-1)
- ax.set_rlabel_position(360)
- barwidth1 = 0.14
- barwidth2 = 0.12
- plt.bar(angle+0.02, radius1, width=barwidth2, align="center",color='darkorange', edgecolor="k", alpha=1, label="HBs")
- plt.bar(angle+barwidth1, radius2, width=barwidth2, align="center",color='steelblue', edgecolor="k", alpha=1, label="XBs")
- plt.legend(loc="best", bbox_to_anchor=(1.2, 0, 0,1),fontsize=24)
- plt.ylim(-1,6)
- plt.xticks(angle+2*np.pi/n_row/4, labels=mydata.index, fontsize=20)
- plt.yticks(np.arange(0,6,1), verticalalignment="center", horizontalalignment="right",fontsize=20)
- plt.grid(which="major", axis="x", linestyle="-", linewidth="0.5", color="gray", alpha=0.5)
- plt.grid(which="major", axis="x", linestyle="-", linewidth="0.5", color="gray", alpha=0.5)
- plt.savefig("./graph/hb_xb_aa_frequency_2.png", dpi=600, bbox_inches = 'tight')
- plt.show()
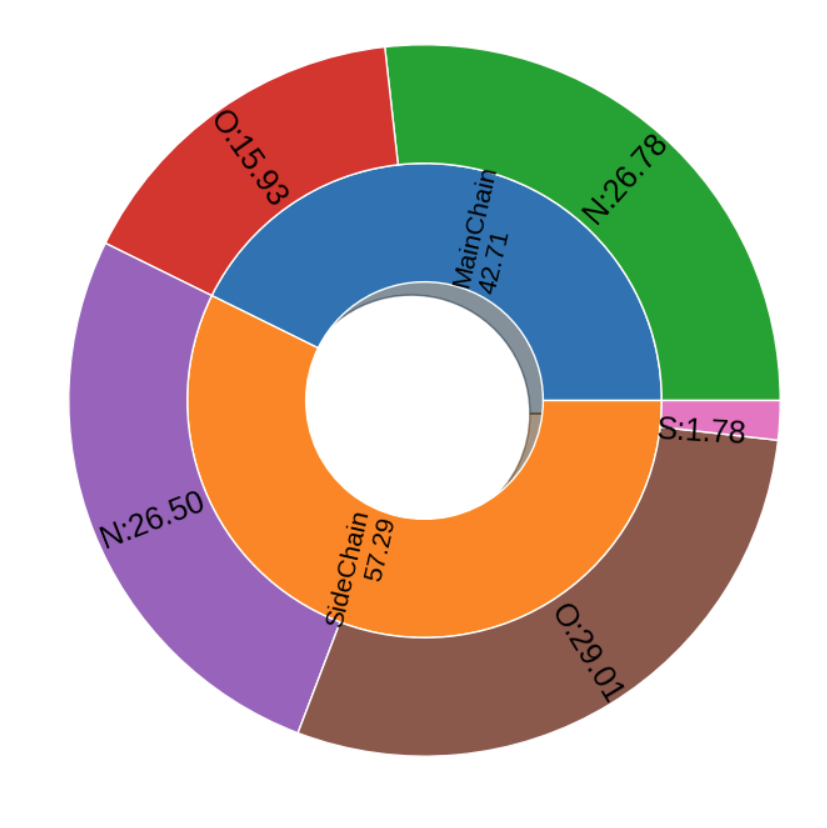
多层饼图
- #统计与小分子形成氢键的主侧链元素分布,多层饼图
- #准备数据,三层的数据分成三组
- X_mainchain = pd.DataFrame()
- X_sidechain = pd.DataFrame()
- #原子symbol为N或者O的就是主链上的原子,剩下的就是侧链
- for key, val in hbonds.groupby(["residue atom name"]):
- if key == "N" or key == "O":
- X_mainchain = pd.concat([X_mainchain,val], axis=0)
- else:
- X_sidechain = pd.concat([X_sidechain, val], axis=0)
- total = hbonds.shape[0]
- layer1_label = ["MainChain", "SideChain"]
- layer1_value = [round(X_mainchain.shape[0]/total,4)*100, round(X_sidechain.shape[0]/total,4)*100]
- layer1_label_value = []
- for i in range(len(layer1_label)):
- layer1_label_value.append(layer1_label[i]+"\n%.2f"%layer1_value[i])
- X_mainchain_O = pd.DataFrame()
- X_mainchain_N = pd.DataFrame()
- for key, val in X_mainchain.groupby(["residue atom elem"]):
- if key == "O" :
- X_mainchain_O = pd.concat([X_mainchain_O,val], axis=0)
- else:
- X_mainchain_N = pd.concat([X_mainchain_N, val], axis=0)
- layer2_main_value = [round(X_mainchain_N.shape[0]/total,4)*100, round(X_mainchain_O.shape[0]/total,4)*100]
- #主链和侧链中N、O、S的比例,算的都是占所有数据的比例
- X_sidechain_O = pd.DataFrame()
- X_sidechain_N = pd.DataFrame()
- X_sidechain_S = pd.DataFrame()
- for key, val in X_sidechain.groupby(["residue atom elem"]):
- if key == "O" :
- X_sidechain_O = pd.concat([X_sidechain_O,val], axis=0)
- elif key == "N":
- X_sidechain_N = pd.concat([X_sidechain_N,val], axis=0)
- else:
- X_sidechain_S = pd.concat([X_sidechain_S, val], axis=0)
- layer2_side_value = [round(X_sidechain_N.shape[0]/total,4)*100, round(X_sidechain_O.shape[0]/total,4)*100, round(X_sidechain_S.shape[0]/total,4)*100]
- layer2_value = layer2_main_value + layer2_side_value
- layer2_label = ["N", "O", "N", "O", "S"]
- layer2_label_value = []
- for i in range(len(layer2_label)):
- layer2_label_value.append(layer2_label[i]+":%.2f"%layer2_value[i])
- #画图
- plt.rcParams['font.sans-serif']=["Liberation Sans"]
- plt.figure(figsize = (12, 10))
- # 获取colormap tab20c和tab20b的颜色
- cmap_a = plt.get_cmap("tab20")
- cmap_c = plt.get_cmap("tab20")
- # 使用tab20c\b的全部颜色
- cmap_1 = cmap_c(np.arange(0,20,2))
- cmap_2 = cmap_a(np.arange(0,20,2))
- # 内圈的颜色是每种颜色中色彩最深的那个. vstack是将两类颜色叠加在一起
- inner_colors = np.vstack((cmap_1[0], cmap_2[1]))
- # 外圈的颜色是全部60种颜色
- outer_colors = np.vstack((cmap_1[2:], cmap_2[5:]))
- size = 0.25
- plt.pie(layer1_value, radius=1-size-size,
- labels=layer1_label_value,
- labeldistance=0.46, rotatelabels=True, textprops={'fontsize': 15},
- colors=inner_colors, wedgeprops=dict(width=size, edgecolor='w'),shadow=True,startangle = 0)
- plt.pie(layer2_value, radius=1-size, colors=outer_colors,
- labels=layer2_label_value,
- labeldistance=0.65, rotatelabels=True, textprops={'fontsize': 18},
- wedgeprops=dict(width=size, edgecolor='w'),startangle =0)
- plt.title("HB Distribution", fontsize=16,loc="center",pad=0)
- plt.tight_layout()
- plt.savefig("./graph/hbonds_protein_mainchain_sidechain_pie_chart.png", dpi=600)
- plt.show()
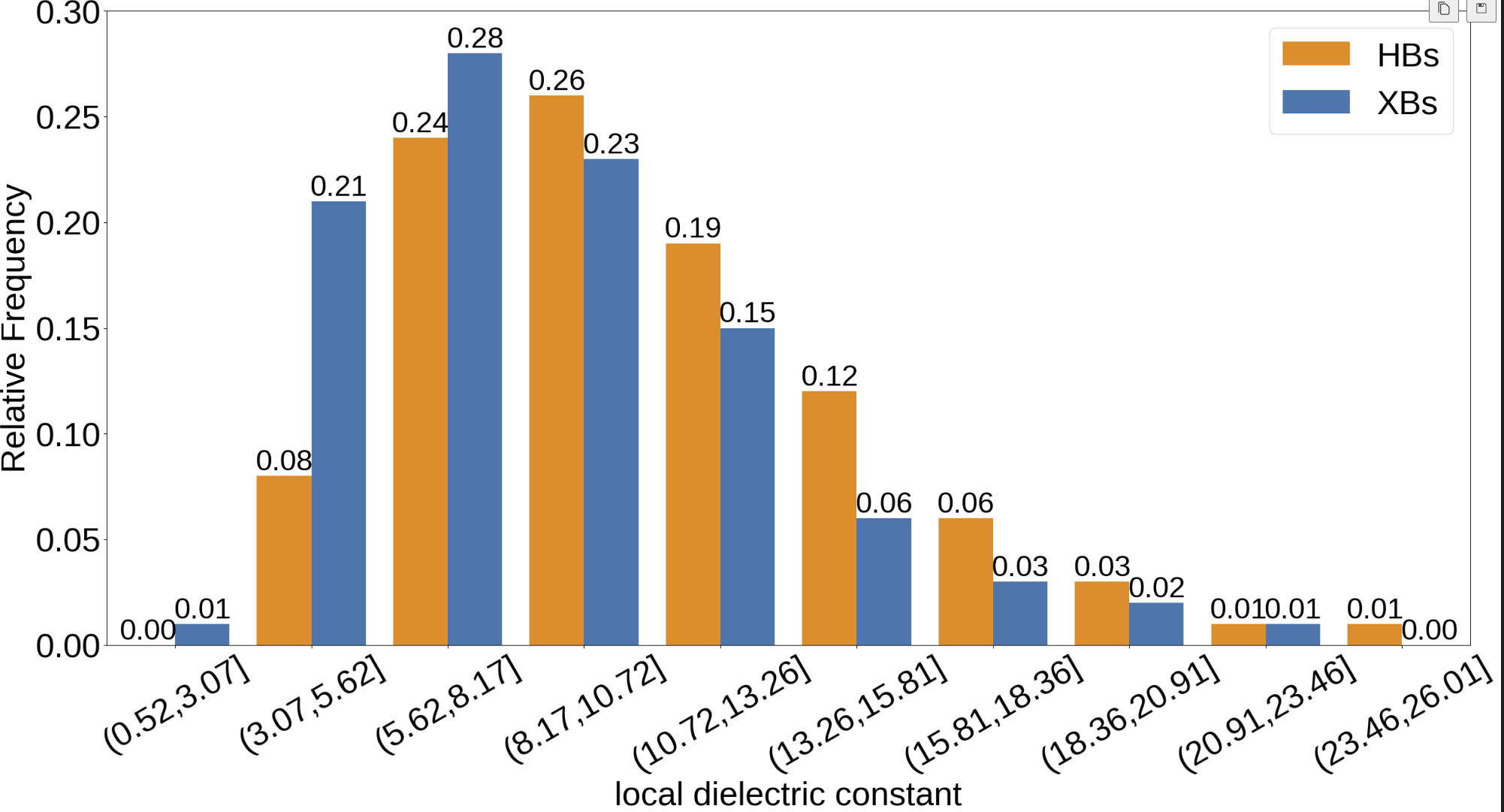
频率分布直方图1
- def generate_bins(min, max, bins_num):
- bins = list(np.around(np.linspace(min-0.1,max+0.1,bins_num),2)) #根据最大值和最小值,均分成10bins
- lables = []
- for i in range(1,len(bins)):
- lable = u'(%s,%s]'%(bins[i-1],bins[i])
- lables.append(lable)
- return bins, lables
- def frequency_calculation(data, bins, lables):
- a_1=pd.cut(data,bins=bins, labels=lables)
- b_1=a_1.value_counts()
- b2_1=b_1.sort_index()
- b2_1 = np.around(b2_1/sum(b2_1),2)
- c_1={'section':b2_1.index,'frequency':b2_1.values}
- e_1=pd.DataFrame(c_1)
- return e_1
- #draw in a big picture, regroup for more detailed info
- property_names = ["local_dielec_cons"]
- subfig = 0
- #fig, ax = plt.subplots(nrows=8,ncols=4,figsize=(48,60))
- fig = plt.figure(figsize=(64,128))
- for property_name in property_names:
- data1 = hbond_df_atm_pro.loc[:,property_name]
- data2 = halogen_df_atm_pro.loc[:,property_name]
- bins,lables = generate_bins(min(min(data1),min(data2)),max(max(data1),max(data2)),26) #根据最大值和最小值,均分成10bins
- e_1 = frequency_calculation(data1, bins, lables)
- e_2 = frequency_calculation(data2, bins, lables)
- #regroup for detail
- min1_for_regroup = float(e_1[e_1["frequency"]>0]["section"].to_list()[0].split(",")[0].strip("("))
- min2_for_regroup = float(e_2[e_2["frequency"]>0]["section"].to_list()[0].split(",")[0].strip("("))
- max1_for_regroup = float(e_1[e_1["frequency"]>0]["section"].to_list()[-1].split(",")[-1].strip("]"))
- max2_for_regroup = float(e_2[e_2["frequency"]>0]["section"].to_list()[-1].split(",")[-1].strip("]"))
- bins,lables = generate_bins(min(min1_for_regroup, min2_for_regroup),max(max1_for_regroup, max2_for_regroup),11) #根据最大值和最小值,均分成10bins
- e_1 = frequency_calculation(data1, bins, lables)
- e_1["bond_form"] = "HBs"
- e_2 = frequency_calculation(data2, bins, lables)
- e_2["bond_form"] = "XBs"
- plt.rcParams['font.sans-serif']=['Liberation Sans']
- ax = fig.add_subplot(8,2,subfig+1) #子图的位置
- #red for HB and cyan for XB
- sns.barplot(x="section",y="frequency",data=pd.concat([e_1,e_2]),hue="bond_form",ax=ax, palette=['darkorange', '#3778bf'])
- ax.set_ylim([0,0.30])
- ax.set_xlabel("local dielectric constant",fontsize=40)
- ax.set_ylabel('Relative Frequency', fontsize=40)
- #ax.set_title('Frequency Distribution', size=20, pad=15)
- plt.xticks(rotation=30, fontsize=40)
- plt.yticks(fontsize=40)
- plt.legend(fontsize=40)
- for x, y in zip(range(10), e_1.frequency): #在每根柱子上标注相应的频数
- ax.text(x-0.2, y, "%.2f"%y, ha='center', va='bottom', fontsize=35, color='k')
- for x, y in zip(range(10), e_2.frequency): #在每根柱子上标注相应的频数
- ax.text(x+0.2, y, "%.2f"%y, ha='center', va='bottom', fontsize=35, color='k')
- subfig += 1
- plt.savefig("HB_XB_env_dielec_cons_5A_atm_proportion_2.png",dpi=300,bbox_inches = 'tight')
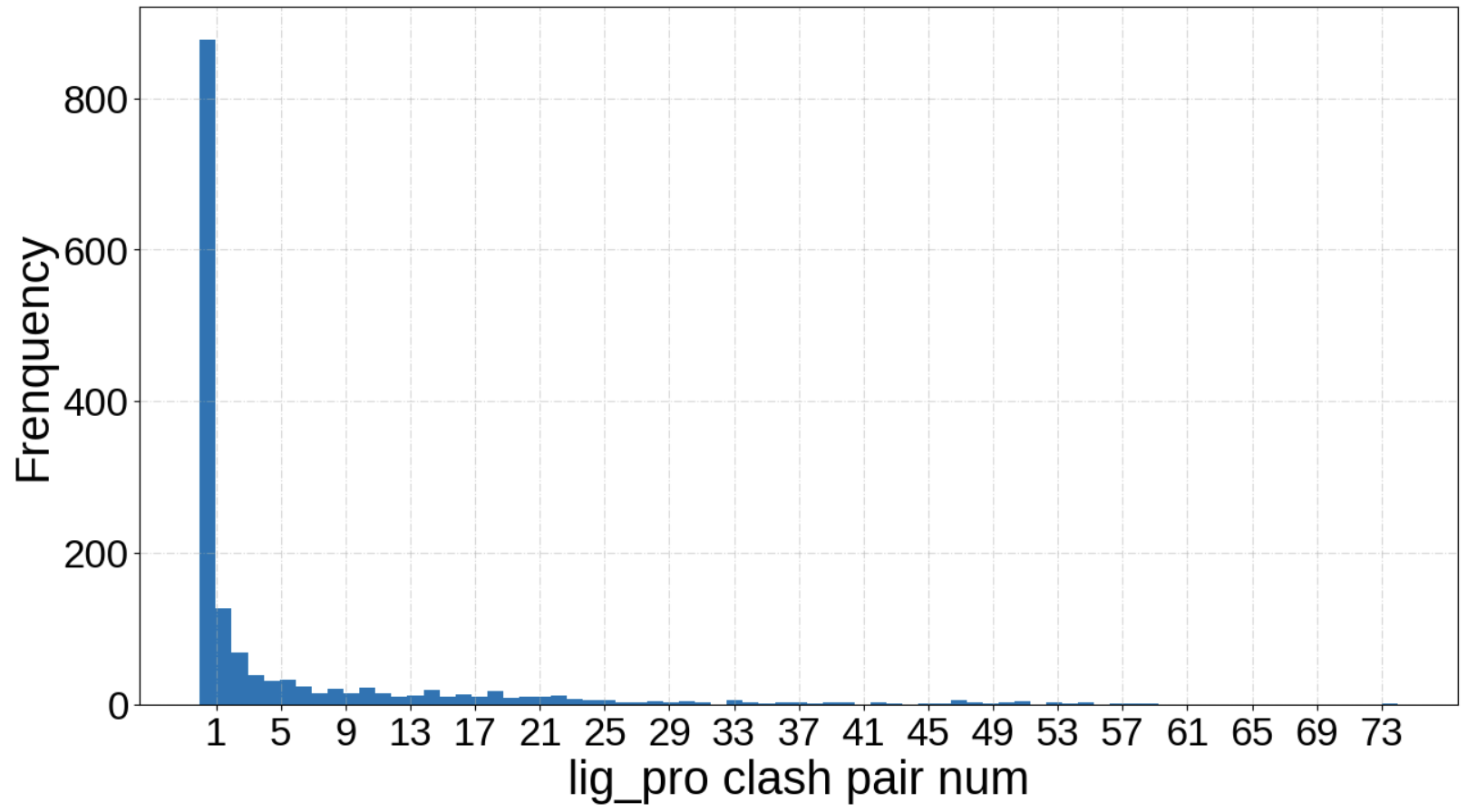
频率分布直方图2
- #频数分布直方图
- plt.figure(figsize=(15,8)) #初始化一张图
- plt.rcParams['font.sans-serif']=['Liberation Sans']
- x = selected_df["lig_pro clash pair num"]
- plt.hist(x, bins=75) #直方图关键操作
- plt.grid(alpha=0.5,linestyle='-.') #网格线,更好看
- plt.xticks(ticks=np.arange(1,75,4), rotation=0, fontsize=25)
- plt.yticks(fontsize=25)
- plt.xlabel('lig_pro clash pair num', fontsize=30)
- plt.ylabel('Frenquency',fontsize=30)
- #plt.title(r'Life cycle frequency distribution histogram of events in New York')
- plt.show()
- plt.savefig("/home/databank/zlp/md-40/PDB_20230208/statistics/graph/all_lig_clash_pair_num_distribution_2.png",dpi=300,bbox_inches = 'tight')
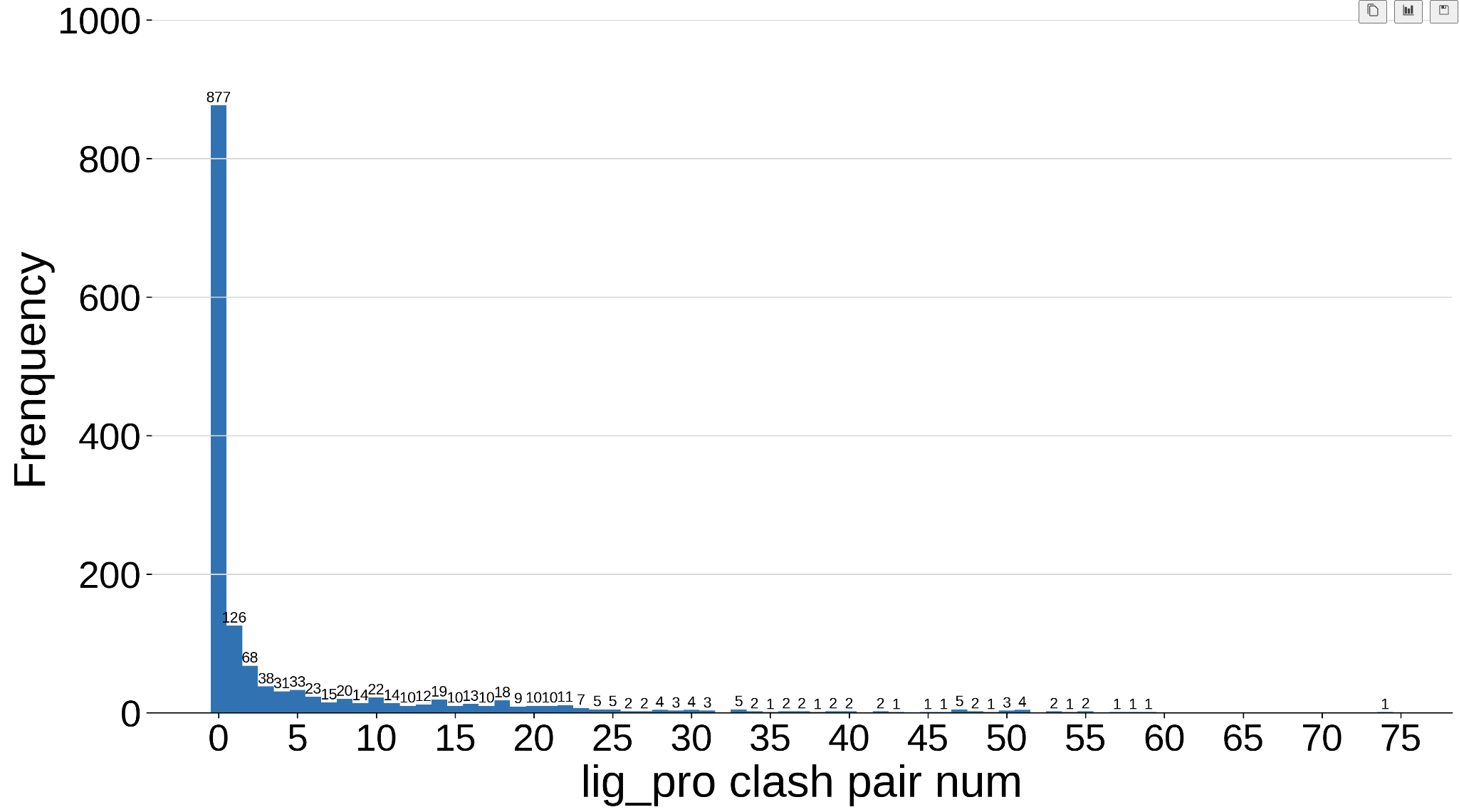
柱状图
- x = selected_df["lig_pro clash pair num"].value_counts().sort_index().index.values
- y = selected_df["lig_pro clash pair num"].value_counts().sort_index()
- fig = plt.figure(figsize=(15, 8), dpi=300)
- plt.subplots_adjust(left=0.1, right=0.9, top=0.9, bottom=0.1)
- plt.grid(axis="y", c=(217/256, 217/256, 217/256)) # 设置网格线
- # 将网格线置于底层
- ax = plt.gca() # 获取边框
- ax.spines['top'].set_color('none') # 设置上‘脊梁’为红色
- ax.spines['right'].set_color('none') # 设置上‘脊梁’为无色
- ax.spines['left'].set_color('none') # 设置上‘脊梁’为无色
- plt.bar(x, y, width=1, align="center")
- for x, y in zip(x,y): #在每根柱子上标注相应的频数
- plt.text(x, y, y, ha='center', va='bottom', fontsize=10, color='k')
- plt.ylim(0, 1000) # 设定x轴范围
- plt.xticks(ticks=np.arange(0,76,5), rotation=0, fontsize=25)
- plt.yticks(fontsize=25)
- plt.xlabel('lig_pro clash pair num', fontsize=30)
- plt.ylabel('Frenquency',fontsize=30)
- plt.show()
- plt.savefig("/home/databank/zlp/md-40/PDB_20230208/statistics/graph/all_lig_clash_pair_num_distribution_2.png",dpi=300,bbox_inches = 'tight')