
一些中药(植物)有关的数据库
化合物嵌入到学习的几种表示:

2024.11.12
ETCM1.0/2.0
1.0里面有402中药,中药配方3959,成分7284,是Xu HY, Zhang YQ, Liu ZM, Chen T, Lv CY, Tang SH, Zhang XB, Zhang W, Li ZY, Zhou RR, Yang HJ, Wang XJ, Huang LQ. ETCM: an encyclopaedia of traditional Chinese medicine. Nucleic Acids Res. 2018 Oct 26. doi: 10.1093/nar/gky987.
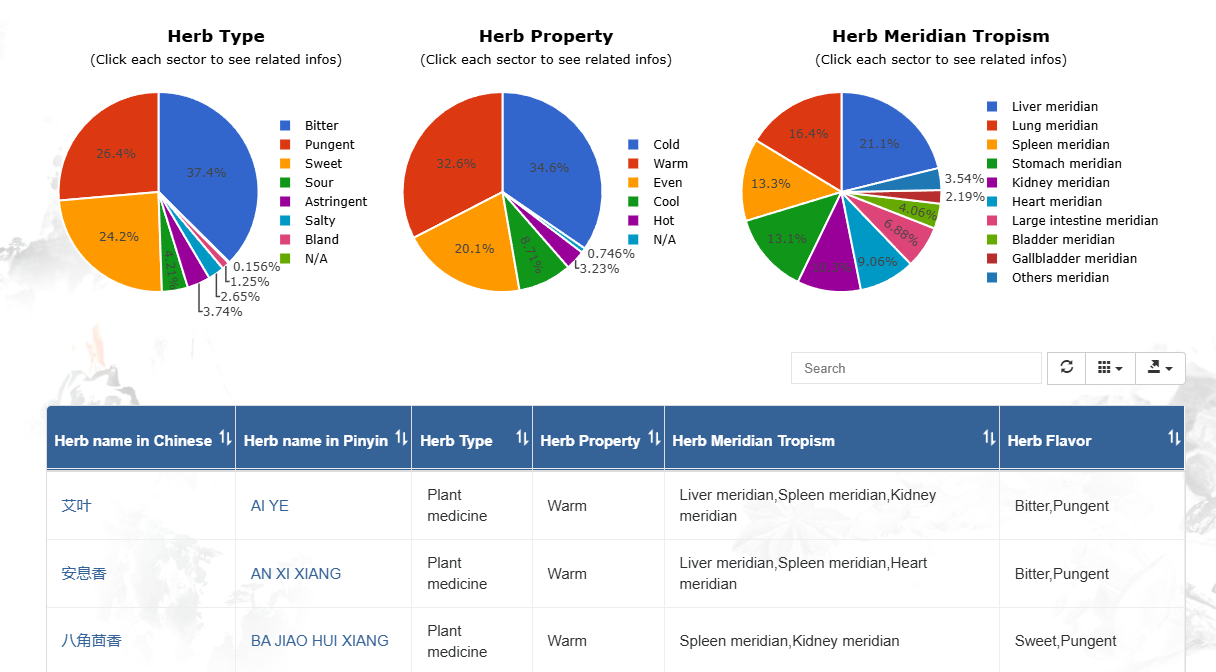
2.0包括319个症状、48442个方剂、9872个中成药、2079个中药材
38298个中药成分、1040个靶标、8045个疾病,是Zhang Y, Li X, Shi Y, Chen T, Xu Z, Wang P, Yu M, Chen W, Li B, Jing Z, Jiang H, Fu L, Gao W, Jiang Y, Du X, Gong Z, Zhu W, Yang H, Xu H. ETCM v2.0: An update with comprehensive resource and rich annotations for traditional Chinese medicine. Acta Pharm Sin B. 2023 Jun;13(6):2559-2571. doi: 10.1016/j.apsb.2023.03.012.
1.0版本:403herbs,7274个中药成分
2.0版本,里面的2079个中药=2005+30矿物(2020药典)+44动物(2020药典)
2005是来源于第四次资源普查、2020药典、其他中医药书籍著作等
经中国中医科学院人工鉴定后,确定的这288个中药寒热确定,且这些数据是化合物数量大于40的

YaTCM
这个数据库已打不开,发了文章就不维护了
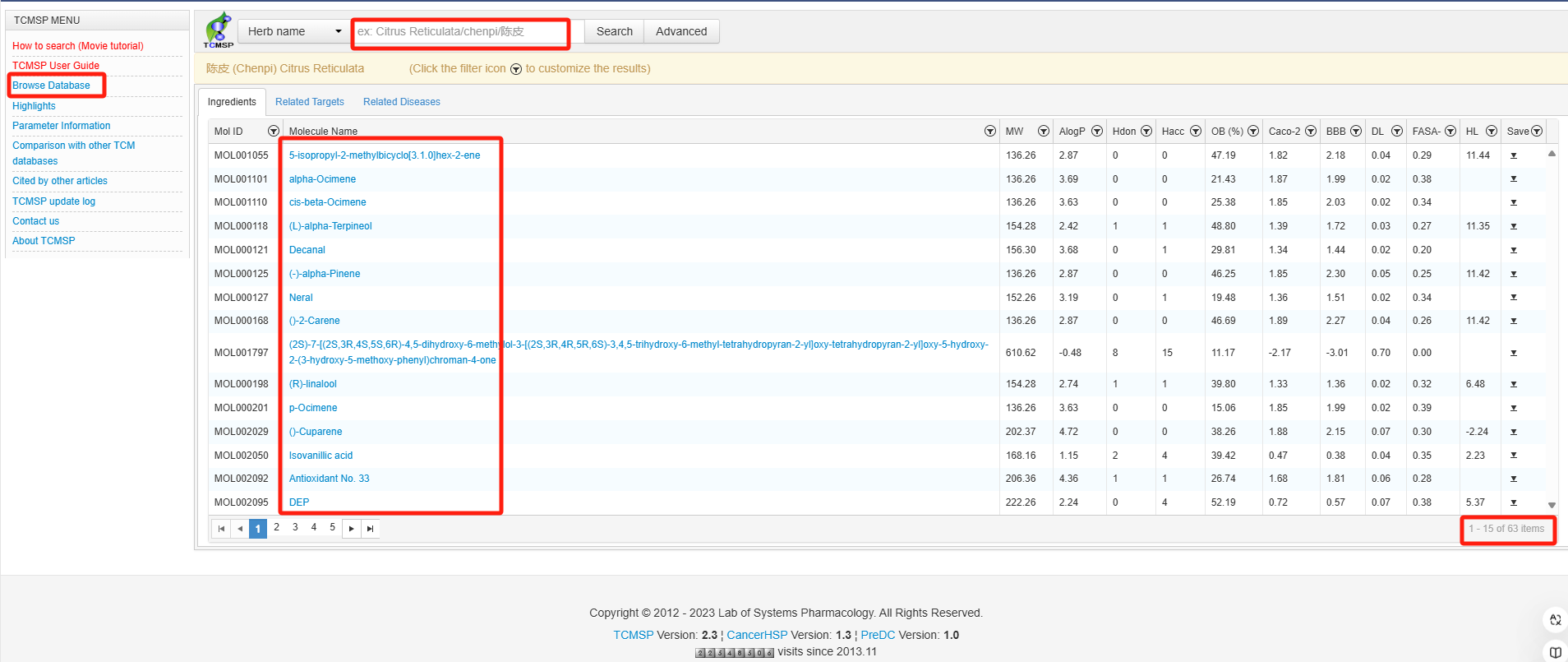
TCMSP
Traditional Chinese Medicine Systems Pharmacology Database and Analysis Platform
没有知道该中药的性质如寒热归经等等、smiles
TCMdatabase
数据下载不了,也看不了形式是什么的

*HIT 2.0
同济大学曹志伟教授课题组开发的草药成分和靶标数据库HIT(Herbal Ingredients' Targets Platform) 的升级版2.0版
还是没有显示中药的一些性质(寒热之类),可进行文献挖掘获取靶标或许以后有用(输入化合物名称,会找pubmed文献摘要里的相关基因)
无法全库下载的

TCMSID


网站进不去估计也是发出来文章就没维护了?待会再看看是否进得去
symmap2.0
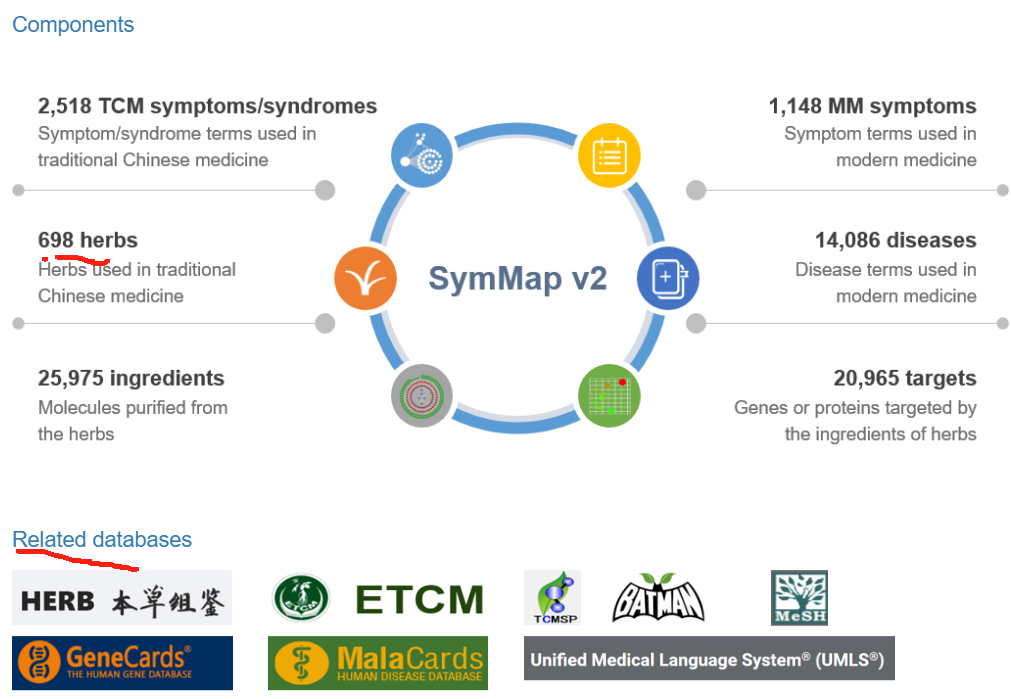
其他都能点开,但是化合物成分那一项点不了
TCMID
主要是方剂类、证候类,靶标类,没有按照中药材分类的
新加坡国立大学药学系生物信息学与药物设计 (BIDD) 小组维护。其数据采集来源于多个国家,提供中医方剂及治病采集(7000+)、中医药成分、化学成分和靶基因、具有基因/蛋白表达测量的人类样本(健康和疾病)、化学数据预处理、基因/蛋白表达数据处理等。主要整合了 TCM-ID(第 1 版)、《中草药名称综合词典》(ISBN:7-5062-3971-X)、SymMap )、ETCM 共 2,751 种成分和约 1,400 种常用草药。从 PubChem 、ChEMBL 、NPASS、ETCM 、SymMap 中整合了当前 TCM-ID 中的 7,375 种草药成分,并从已发表的论文中提取
*本草组鉴HERB

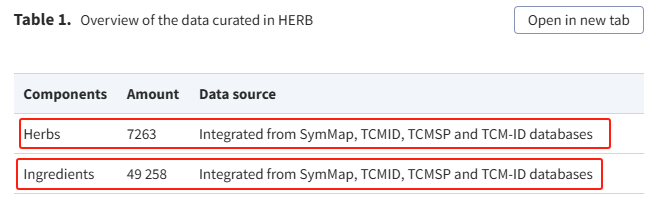
需要输入中药名,有成分,需要一个一个成分点击进去加载再下载,很慢。若是用到靶标基因等,这个网站稍方便。
wget?
+ for 循环
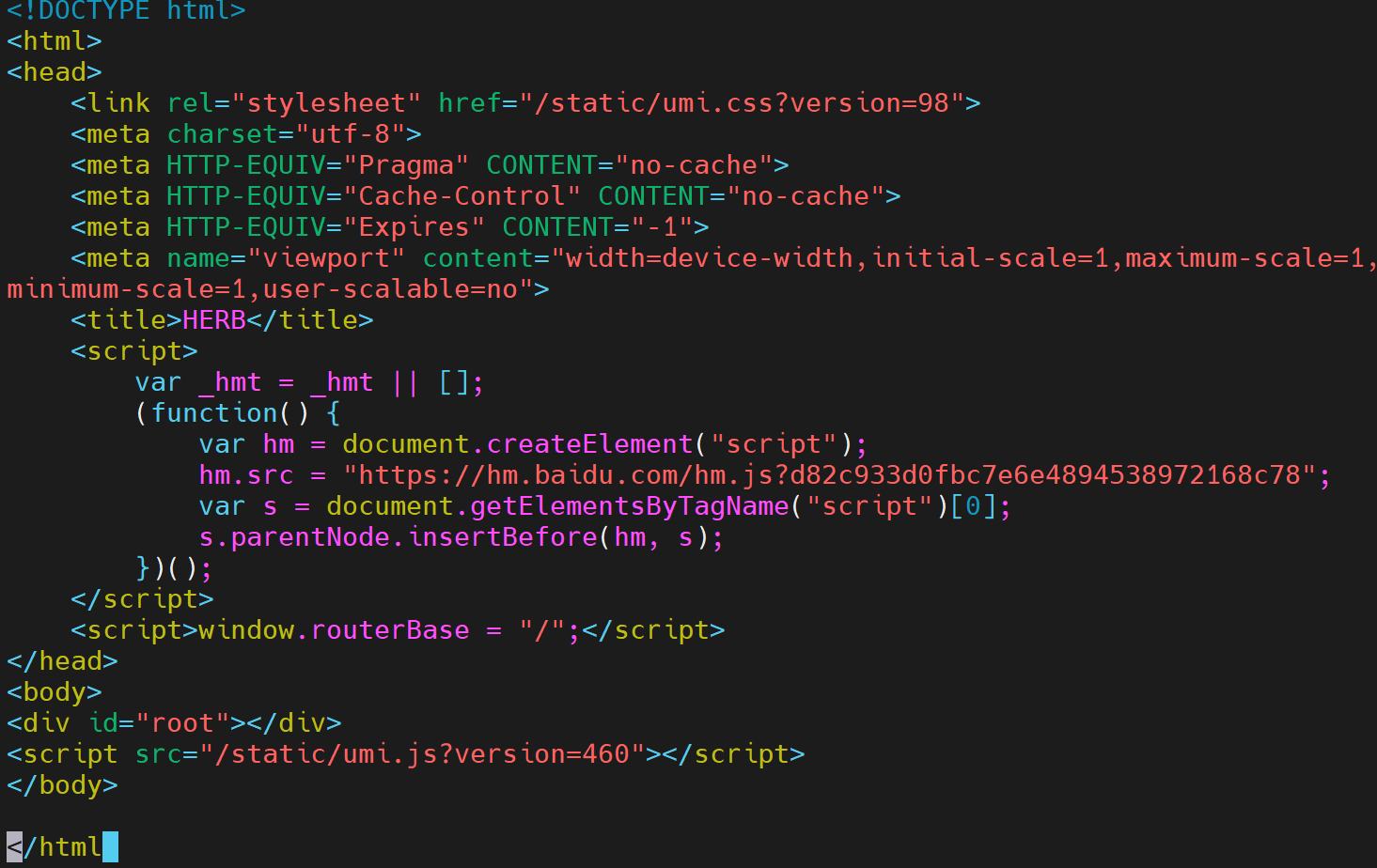
wget 只会下载页面的静态 HTML,无法执行 JavaScript,因此无法获取到动态渲染后的完整内容。
尝试爬虫下载?
尝试1-requests
- import os
- import requests
- from bs4 import BeautifulSoup
- import time
- # 创建保存文件的目录
- save_dir = "/home/databank_70t/chenyuanjie/outdoor_data/20241125_test_down_from_web
- "
- os.makedirs(save_dir, exist_ok=True)
- # 需要爬取的编号范围
- start_id = 1 # 起始编号
- end_id = 2 # 结束编号(根据需要调整)
- base_url = "http://herb.ac.cn/Detail/?v=HERB{:06d}&label=Herb"
- for herb_id in range(start_id, end_id + 1):
- herb_number = f"HERB{herb_id:06d}" # 格式化为 HERB000001
- url = base_url.format(herb_id)
- print(f"Processing {herb_number}: {url}")
- try:
- # 请求页面内容
- response = requests.get(url)
- response.raise_for_status()
- soup = BeautifulSoup(response.text, 'html.parser')
- # 定位页面中最后一个“Download”按钮
- all_download_buttons = soup.find_all('a', text="Download")
- if all_download_buttons:
- # 获取最后一个按钮
- download_button = all_download_buttons[-1]
- download_url = download_button['href']
- print(f"Found download link: {download_url}")
- # 下载文件内容
- file_response = requests.get(download_url)
- file_response.raise_for_status()
- # 保存文件
- file_path = os.path.join(save_dir, f"{herb_number}.txt") # 文件命名
- with open(file_path, 'wb') as file:
- file.write(file_response.content)
- print(f"Downloaded and saved: {file_path}")
- else:
- print(f"No download link found for {herb_number}")
- except Exception as e:
- print(f"Failed to process {herb_number}: {e}")
- # 防止请求过快,避免被网站封禁
- time.sleep(1)
查看网页源码,若是找到链接说明是静态加载的可以直接用requests库获取,而没有找到链接说明可能是通过JavaScript动态生成的,需要工具如selenium模拟浏览器行为。
上面代码运行显示
Processing HERB000001: http://herb.ac.cn/Detail/?v=HERB000001&label=Herb
No download link found for HERB000001Processing HERB000002: http://herb.ac.cn/Detail/?v=HERB000002&label=HerbNo download link found for HERB000002

尝试2-selenium
Firefox浏览器60.8.0,驱动0.20.1
- from selenium import webdriver
- from selenium.webdriver.firefox.service import Service
- from selenium.webdriver.common.by import By
- from selenium.webdriver.support.ui import WebDriverWait
- from selenium.webdriver.support import expected_conditions as EC
- import os
- import time
- import glob
- # 配置下载目录
- download_directory = "/home/databank_70t/chenyuanjie/outdoor_data/20241125_test_down_from_web" # 修改为你想保存文件的路径
- if not os.path.exists(download_directory):
- os.makedirs(download_directory)
- # 配置 Selenium
- options = webdriver.FirefoxOptions()
- options.set_preference("browser.download.folderList", 2) # 使用自定义下载目录
- options.set_preference("browser.download.dir", os.path.abspath(download_directory))
- options.set_preference("browser.helperApps.neverAsk.saveToDisk", "application/xlsx") # 指定文件类型,防止弹窗
- options.headless = True # 无头模式,适合无图形界面环境
- # 配置 Geckodriver 的路径
- service = Service(executable_path='/home/databank_70t/chenyuanjie/apps/geckodriver')
- # 启动 WebDriver
- driver = webdriver.Firefox(service=service, options=options)
- # 等待下载函数
- def wait_for_download(directory, timeout=30):
- elapsed = 0
- while elapsed < timeout:
- files = glob.glob(f"{directory}/*.part")
- if not files: # 没有部分下载文件,表示下载完成
- return True
- time.sleep(1)
- elapsed += 1
- raise TimeoutError("Download did not complete in time")
- # HERB ID 范围
- start_id = 1
- end_id = 3
- # 循环下载每个 HERB ID 的文件
- for herb_id in range(start_id, end_id + 1):
- herb_str = f"HERB{herb_id:06d}" # 格式化为 HERB000001, HERB000002...
- url = f"http://herb.ac.cn/Detail?v={herb_str}&label=Herb"
- try:
- # 打开对应的页面
- driver.get(url)
- # 找到 "Download" 按钮并点击
- download_button = WebDriverWait(driver, 10).until(
- EC.element_to_be_clickable((By.XPATH, '//button[text()="Download"]'))
- )
- download_button.click()
- # 等待文件下载完成
- wait_for_download(download_directory)
- # 重命名文件
- downloaded_files = os.listdir(download_directory)
- for file in downloaded_files:
- if file.endswith(".xlsx"):
- old_path = os.path.join(download_directory, file)
- new_path = os.path.join(download_directory, f"{herb_str}.xlsx")
- os.rename(old_path, new_path)
- print(f"Downloaded and renamed: {new_path}")
- break
- except Exception as e:
- print(f"Error processing {herb_str}: {e}")
- # 关闭 WebDriver
- driver.quit()
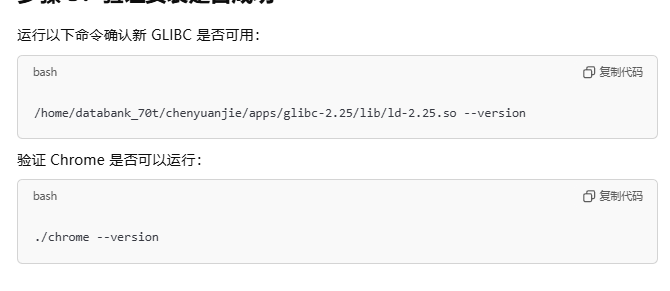
下载chrome浏览器?
./chrome --version
./chrome: /lib64/libc.so.6: version GLIBC_2.25' not found (required by ./chrome)
tar -xvf glibc-2.25.tar.gz
mkdir build
cd build

crul-
张老师尝试,还是未能下载下来。
联系作者?无果-可能是由于这是关键数据吧


尝试先筛选条件,然后自己下载
400+个
TCMBank-中山大学
2024.12.3
按照同样的标准来看看下有多少中药。
化合物数量,中药性质
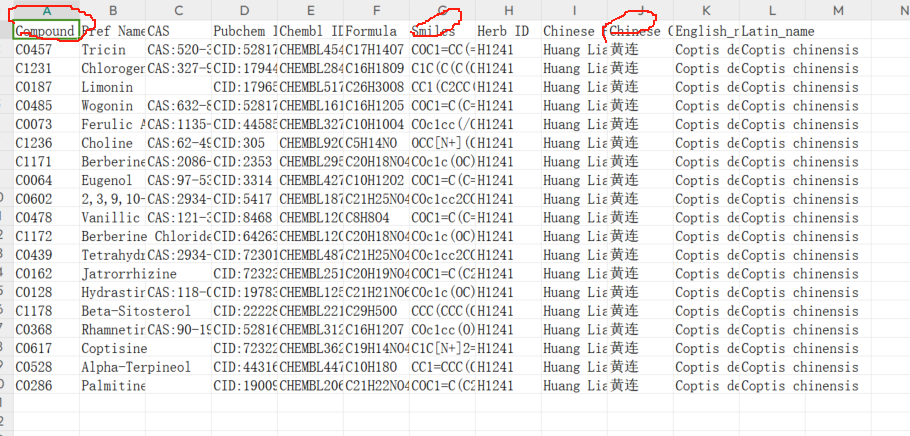
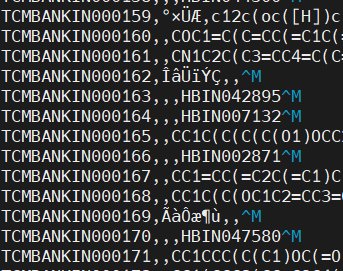
ingredient_all.csv:
sed -i 's/Warm/温/g' chinese_properity_821.txt
sed -i 's/Cold/寒/g' chinese_properity_821.txt
sed -i 's/Mild/平/g' chinese_properity_821.txt
sed -i 's/Minor Warm/微温/g' chinese_properity_821.txt
sed -i 's/Hot/热/g' chinese_properity_821.txt
sed -i 's/Cool/凉/g' chinese_properity_821.txt
sed -i 's/Minor cold/微寒/g' chinese_properity_821.txt
成分表,中文乱码以及最后有M,excel和服务器转换的问题,gpt搜索可改正常