
20240826 MD procedure
基于20240825 晚和乐云师姐的讨论,开展以下工作
trypsin-inhibitors 体系
trypsin-inhibitors
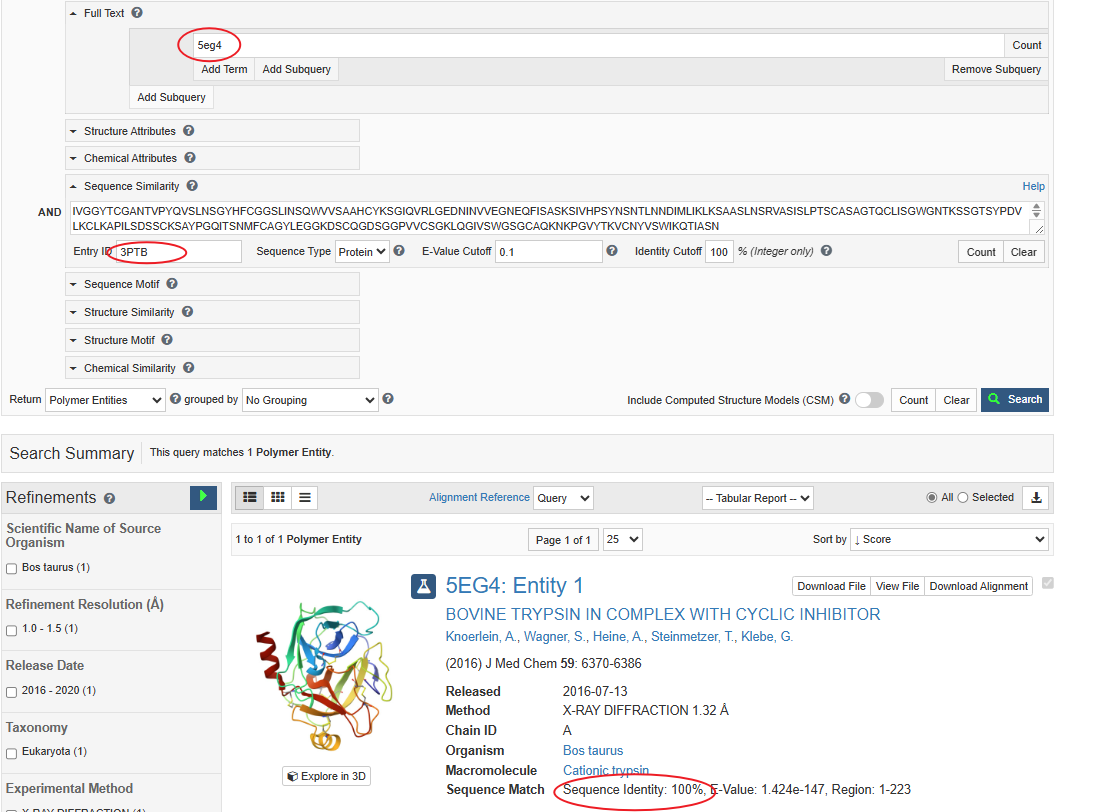
3PTB和5eg4序列比对
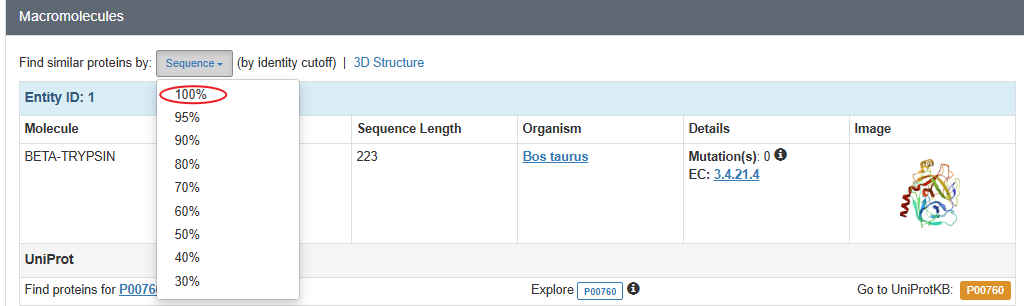
进入3PTB的PDB界面,find similar proteins by sequence 100%,
配体准备
- # 22224
- # 172.21.85.24
- # 使用薛定谔优化结构(图形化界面操作)
- # pH = 8.0,手性从3D结构定(晶体结构),力场为2017版的默认力场OPLS3
- # 高斯优化
- # 原始文件 /home/databank/lywu/trypsin/inhibitiors/gaussian_job
- # 注意检查体系的电荷和自选多重度
- antechamber -i lig.sdf -fi sdf -o lig.gjf -fo gcrt -at gaff2 -gn "%nproc=4" -gm "%mem=4GB" -gk "#B3LYP/6-31G* em=gd3bj pop=MK iop(6/33=2,6/42=6) opt" -rn MOL -nc 0
- # 上述工作乐云师姐已完成,高斯优化已完成,拿到了log文件
- ###################################################################################
- # 以下工作由我接手
- # 85.24 /home/databank/zzy/project/MD/koff/trypsin/ligprep-opt
- # 基于高斯优化日志文件,拟合RESP电荷,生成AMBER需要的参数文件(prep)
- conda activate ambertools
- for i in
`ls`;do cd $i;antechamber -i lig.log -fi gout -o lig.prep -fo prepi -c resp;parmchk2 -i lig.prep -f prepi -o lig.frcmod -a y;cd ../;done

- antechamber -i ensitrelvir.log -fi gout -o ensitrelvir.prep -fo prepi -c resp
- # 这一步生成的NEWPDB.PDB 很重要
- parmchk2 -i ensitrelvir.prep -f prepi -o ensitrelvir.frcmod -a y
- # 这一步本质上是获得坐标,尝试直接从晶体结构中抠出小分子,提取坐标
- # gv里分别打开 NEWPDB.PDB 与 5eg4_ligand_native_277.mol2(晶体结构配体文件)
- # 打开GV tools-atom list-鼠标点击symbol列-rows-sort selected -拖动鼠标选择所有H-edit-delete-selected atoms),接着仍在atom list中,edit-z matrix-standardize,分别保存<步骤一>。
- # 得到 g16-gv.pdb crystal-gv.pdb
- # GV里 检查 g16-gv.pdb crystal-gv.pdb,更改crystal-gv.pdb (atom list - Tag),使其Tag 与g16-gv.pdb 完全一致。
- # 20240826 经乐云师姐指正,参考子涧师兄20230703的提出的方法,<步骤一>完成后,两个文件的原子index是一致的,无需再对(atom list - Tag)做修改。
- # 注意:输入的文件晶体结构文件需要是sdf文件!mol2无法成功
- # 20240806 检查发现,并不行,原子对不上
- dos2unix *
- grep -v "CONECT" g16-gv.pdb |cut -b 1-26 > symbol
- cat crystal-gv.pdb | cut -b 29-78|sed '1,2d'|sed '1i Combineing the coordinates from the crystal structure with the atomic numbers from the Gaussian optimized structure'> coordinate
- paste -d " " symbol coordinate|sed '1i TITLE lig.pdb'> lig.pdb
- ### 可视化检查
受体准备
- # PDBBIND
- # /home/databank/zzy/project/MD/koff/trypsin/pro-pre/pdbbind
- conda activate pdb2pqr
- pdb2pqr30 5eg4_ligand_native_277_protein.pdb 5eg4_pred.pqr --ff AMBER --ffout AMBER --with-ph 8.0 --pdb-output 5eg4_pred.pdb
- # 直接从PDBBIND蛋白结构出发,用tleap读取,存成新的蛋白文件,再进行二硫键相关的处理
- # /home/databank/zzy/project/MD/koff/trypsin/pro-pre
- tleap -f tleap-pdbclean.in
- # 得到 5eg4-pdb2pqr-tleap.pdb
- # 二硫键的特殊处理
- 1)找到形成二硫键的氨基酸,把残基名字改为CYX;
- 2)删掉CYX的所有H;
- 3)用tleap中的bond连接二硫键,可以在cpptraj中的trajout output.pdb conect命令中输出CONET信息检查
- grep -v "H CYX" 5eg4-pdb2pqr-tleap.pdb|grep -v "HA CYX"|grep -v "HB2 CYX"|grep -v "HB3 CYX" >pro-tleap.pdb
- (ambertools) [lywu@localhost pro-pre]$ wc -l 5eg4_pred.pdb 5eg4-pdb2pqr-tleap.pdb pro-tleap.pdb
- 3221 5eg4_pred.pdb
- 3222 5eg4-pdb2pqr-tleap.pdb
- 3174 pro-tleap.pdb
- # /home/databank/zzy/project/MD/koff/trypsin/complex-pre/trypsin-31
- # 发现PDB2PQR处理得到的蛋白质已经没有名字为CYS的氨基酸了,都是CYX
- # 删除氢原子的时候发现有12个(6对)CYX,各自有4个H(H,HA,HB2,HB3},总共48个,但是删掉后比原来少了13个。。
- ##################################################################################
- (base) [lywu@localhost trypsin-31]$ wc -l 5eg4_pred_CYX_cleaned.pdb
- 3174 5eg4_pred_CYX_cleaned.pdb
- (base) [lywu@localhost trypsin-31]$ grep -v "H CYX" 5eg4_pred.pdb|grep -v "HA CYX"|grep -v "HB2 CYX"|grep -v "HB3 CYX"|wc -l
- 3174
- (base) [lywu@localhost trypsin-31]$ wc -l 5eg4_pred.pdb
- 3221 5eg4_pred.pdb
- (base) [lywu@localhost trypsin-31]$ grep CY 5eg4_pred.pdb |grep H|wc -l
- 48
- ##################################################################################
- # 5eg4_pred_CYX_cleaned.pdb是手动删除的
- # 先用 5eg4_pred_CYX_cleaned.pdb往下做
- tleap 重新输出结构后该问题解决
复合物准备
- # /home/databank/zzy/project/MD/koff/trypsin/complex-pre/trypsin-31
- # tleap
- source leaprc.protein.ff19SB
- source leaprc.gaff2
- source leaprc.water.opc
- loadamberparams /home/databank/zzy/project/MD/koff/trypsin/ligprep-opt/g16/31/lig.frcmod
- loadamberprep /home/databank/zzy/project/MD/koff/trypsin/ligprep-opt/g16/31/lig.prep
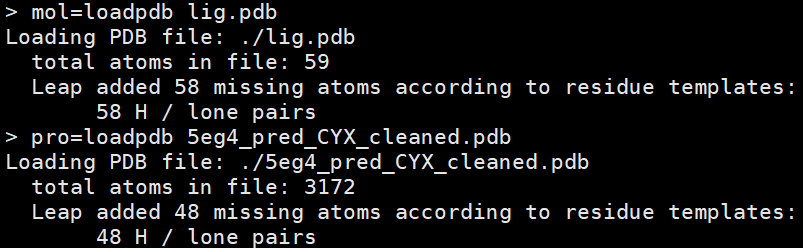
- mol=loadpdb lig.pdb
- pro=loadpdb pro-tleap.pdb
- bond pro.7.SG pro.137.SG
- bond pro.25.SG pro.41.SG
- bond pro.173.SG pro.197.SG
- bond pro.162.SG pro.148.SG
- bond pro.116.SG pro.183.SG
- bond pro.109.SG pro.210.SG
- 报错了,发现蛋白质中存在缺失的氨基酸,序号对不上
- 发现师姐的那个3PTB也是一样的问题,开头的序号不是1,中间有缺失的氨基酸(例如:34后面直接跟的就是37)
- solution: 直接用tleap读取蛋白结构,保存一个新的出来
- com=combine {pro mol}
- saveamberparm pro pro.prmtop pro.inpcrd
- saveamberparm mol lig.prmtop lig.inpcrd
- saveamberparm com native.prmtop native.inpcrd
- savepdb com com-dry.pdb
- #检查电荷
- charge com
- solvatebox com OPCBOX 10
- # 1.5 Calculating Salt Molarity in an Explicit Water System (ambermd.org)
- addionsrand com Na+ 24 Cl- 32
- # 计算电荷(检查是否为0,有浮点数无妨)
- charge com
- saveamberparm com complex.prmtop complex.inpcrd
- savepdb com com.pdb
- # 二硫键的特殊处理
- 1)找到形成二硫键的氨基酸,把残基名字改为CYX;
- 2)删掉CYX的所有H;
- 3)用tleap中的bond连接二硫键,可以在cpptraj中的trajout output.pdb conect命令中输出CONET信息检查
- parm ../native.prmtop
- trajin ../com-dry.pdb
- trajout test.pdb conect
- run
- # 是检查prmtop文件的键连信息
- # 除此以外,也可以检查topol文件的键连信息(bond部分)
- #进入python
- import parmed as pmd
- amber = pmd.load_file('complex.prmtop','complex.inpcrd')
- amber.save('topol.top')
- amber.save('gromacs.gro')
- #修改topol.top 与 gromacs.gro
- sed -i "s/WAT/SOL/g" topol.top
- sed -i "s/system1/Protein/g" topol.top
- ######################################################################
- # 20240826 完成到这一步 SMD是否需要位置限制?网络波动,有道云打不开
- # 0827 冲!
- # 在蛋白质结束和小分子开始前添加位置限制(moleculetype)
- sed -i '36213 a ; Include Position restraint file\n#ifdef POSRES\n#include "posre1.itp\n#endif\n' topol.top
- # 在小分子结束和离子开始前添加位置限制(moleculetype)
- sed -i '37434 a ; Include Position restraint file\n#ifdef POSRES\n#include "posre2.itp\n#endif\n' topol.top
- sed -i "s/WAT/SOL/g" gromacs.gro
- gmx_mpi make_ndx -f gromacs.gro -o index.ndx
- > 1|13
- # 位置限制文件只是个索引,规定了哪些原子被限制
- gmx_mpi genrestr -f gromacs.gro -o posre1.itp
- sed -n '1,62p' posre1.itp > posre2.itp
- 关于mdp文件的一些注意事项:
- 1. 同一个工作中mdp一定要一致
- 2. 尽量不要出现 warning ,若出现,仔细检查
体系平衡
- # /home/databank/zzy/project/MD/koff/trypsin/complex-pre/trypsin-31/pre-equilibrium
- mkdir em nvt npt mdp
- cp /home/databank/lywu/vsremd_plus/protein-ligand/trypsin-benzamidine/pre-equilibrium/mdp-file/* ./mdp/
- # nvt,npt 都改成200ns
- ### 能量最小化
- # /home/databank/zzy/project/MD/koff/trypsin/complex-pre/trypsin-31/pre-equilibrium/em
- gmx_mpi grompp -f ../mdp/em.mdp -c ../gmx.gro -r ../gmx.gro -p ../topol.top -o em.tpr
- nohup mpirun -np 100 gmx_mpi mdrun -v -deffnm em &
- ### 等温等容预平衡
- # /home/databank/zzy/project/MD/koff/trypsin/complex-pre/trypsin-31/pre-equilibrium/nvt
- gmx_mpi grompp -f ../mdp/nvt.mdp -c ../em/em.gro -r ../em/em.gro -p ../topol.top -o nvt.tpr
- nohup mpirun -np 100 gmx_mpi mdrun -v -deffnm nvt &
- ### 等温等压预平衡
- # /home/databank/zzy/project/MD/koff/trypsin/complex-pre/trypsin-31/pre-equilibrium/npt
- gmx_mpi grompp -f ../mdp/npt.mdp -c ../nvt/nvt.gro -r ../nvt/nvt.gro -p ../topol.top -o npt.tpr
- nohup mpirun -np 100 gmx_mpi mdrun -v -deffnm npt &
- 对于该体系,nvt不跑,体系会崩溃,即使先1fs,再2fs,或者1fs后再能量最小化,也是会崩溃
- 但是这种调试的方法,确实会逐渐使体系稳定(npt能跑更多的步数,一开始跑10几步报错,后买你300多步报错)
SMD
复制师姐的dat 文件,smd.sh , mdp文件
复制自己的top文件,npt结构文件,正则化命名
dat 文件里的
ligand: COM ATOMS=2472
active-residue: COM ATOMS=3225
是根据CV来的,需要根据我们自己体系里的原子index修改(这个体系里,都用苯甲脒上的苄基碳和对应的关键resn ASP189上的羧基碳)
修改后,检查sh 文件里的核数,可以跑SMD(google 有空看一下参数)
跑出来会得到 smd${I}.gro, 检查是否成功的将小分子拉出来了,若没有,可增加副本数(多20个拉的距离很远的副本),一定要拿到小分子在 on/off 路径上 的一系列 构象。
用这些构象,去泡vsREMD/..
- # 24上的SMD很慢,去23上跑
- # 85.23 /home/databank_70t/zzy/project/koff/trypsin-31/smd
- scp -r lywu@172.21.85.24:/home/databank/zzy/project/MD/koff/trypsin/complex-pre/trypsin-31 ./
- cp ../pre-equilibrium/npt/npt.gro ./
- cp ../pre-equilibrium/topol.top ./gmx.top
- 在npt.gro里找到对应的原子index
- ligand: COM ATOMS=2472
- active-residue: COM ATOMS=33


- 做到这一步突然发现 CA离子没加,回去 去加离子
- 在 tleap 加载的那个蛋白文件里加
- 这个问题的 ”根源“是PDBBIND里没加 钙离子!!!!(-_-)
vsREMD
- # pymol 里看SMD的结果,挑选20个构象
- # 85.23 /home/databank_70t/zzy/project/koff/trypsin-31/smd/40loop/gro-check/vsremd-select
- for i in {0,10,13,15,17,21,24,25,27,28,29,31,32,33,34,35,36,37,38,39};do cp ../smd${i}.gro ./;done
- ls > index
- for i in {1..20};do b=
`sed -n "${i}p" index`;mv $b smd-select${i}.gro;done - # 85.24 /home/databank/zzy/project/MD/koff/trypsin/vsremd/trypsin-31/smd-select
- for i in {0..19};do a=
`expr ${i} + 1`;mv smd-select${a}.gro smd-select${i}.gro;done - # /home/databank/zzy/project/MD/koff/trypsin/vsremd/trypsin-31
- nohup sh -c 'for i in {0..19};do a=
`expr ${i} + 1`; b=`sed -n "${a}p" temp`; mkdir md$i; sed "s/300.00/${b}/g" md.mdp > md$i/md.mdp; cd md$i; gmx_mpi grompp -f md.mdp -p ../gmx.top -n ../index.ndx -r ../smd-select/smd-select${i}.gro -c ../smd-select/smd-select${i}.gro -o md.tpr; cd ../; done' - source ~/.gmx2022.5-vsremd.sh
- nohup mpirun -np 100 gmx_mpi mdrun -v -deffnm md -multidir md0 md1 md2 md3 md4 md5 md6 md7 md8 md9 md10 md11 md12 md13 md14 md15 md16 md17 md18 md19 -replex 1000 &