vsREMD GPU
0830
- 测试所需文件存放路径:172.21.75.1 /home/dddc/zjhan/vsREMD-GPU/file/6replica
调用GPU的命令
- 1. 命令行输入(优先级最高)
- # 若只指定一个GPU,GMX自带的-gpu_id 将无法调用其他GPU
- export CUDA_VISIBLE_DEVICES=1
- # 若指定多个,GMX自带的-gpu_id 只能调用指定的这部分GPU
- export CUDA_VISIBLE_DEVICES=0,1,2
- # 若不输入该命令,GMX默认可以调用所有的GPU。与写入所有GPU ID等价
- export CUDA_VISIBLE_DEVICES=0,1,2,3
- 2. GMX mdrun板块自带参数 -gpu_id
- nohup gmx_mpi mdrun -v -deffnm test -gpu_id 3 &
线程数设置
经测试(如下图),调用20个左右速度最快
- export OMP_NUM_THREADS=20

0927 online discussion
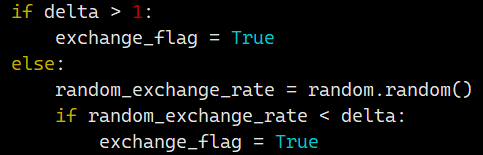
- 交换的有点频繁,每100步算一次(mdp nstep: 100)。在task_log.log 里可见,一直在交换(exchange_flag = True)。定位到运行脚本 MDRunner.py 里, leyun提出 当delta <1时,应该是小于随机数才交换? 我和师兄都很疑惑。17:02 ,leyun找到了2020年的笔记,证实了是大于随机数才交换,并给出了极好的解释:常规情况下,高温副本比低温副本能量更高,因此,若高温副本能量更低,直接交换;若能量更高,则通过与随机数的比较,给他一个机会交换
- 为了做测试,检查我们跑很短的步数,计算得到的势能。要先给定一样的初始速度,去测试(初始应该是gen_seed = 123,后面就是 gen_vel = no; continuation = yes;gen_temp = +++)
- Leyun: gen_vel 默认是 yes,gen_seed = -1 是随机速度(与 gen_vel = no 冲突)
- gen_vel continuation gen_temp gen_seed 对初始速度的影响,gen_temp与 ref_t的优先级顺序,看手册
- gmx 报错原因找到了,初始构象的gro里速度是nan(速度校正因子是负值)
1010
85.24 /home/databank/zzy/project/MD/vsREMD-gpu
- for a in {1..6};do mkdir md$a;b=
`sed -n "${a}p" file/temp`;sed "s/300.00/${b}/g" file/output_every_step.mdp >md$a/md.mdp;gmx_mpi grompp -f md$a/md.mdp -c zjhan-gpu4n-gro/replica_$a/run.gro -p file/topol.top -n file/index.ndx -o md$a/md.tpr;done - nohup mpirun -np 60 gmx_mpi mdrun -v -deffnm md -multidir md1 md2 md3 md4 md5 md6 -replex 10 &
1011
- nohup mpirun -np 60 gmx_mpi mdrun -v -deffnm md -multidir md1 md2 md3 md4 md5 md6 -replex 10 &
- # 1010 的轨迹,只跑了100步,每一步都输出log,能量,速度,坐标信息,每10步判断一次是否交换
- # debug 思路:将需要判断交换的那6帧(每个副本一帧)提取出来,运行vsREMD-GPU的脚本,看我们计算得到的能量和vsREMD-CPU log文件里的是否一致
- # 测试一下pbc是否有影响
- 有影响!!!
- mkdir sep
- # pbc (不进行pbc处理)
- for i in {1..6};do echo 0|gmx_mpi trjconv -f ../../../md$i/md.xtc -s ../../../md$i/md.tpr -n ../../../../file/index.ndx -sep -o md$i-.gro;done
- # nopbc (进行pbc处理)
- for i in {1..6};do echo 0|gmx_mpi trjconv -f ../../../md$i/md.xtc -s ../../../md$i/md.tpr -n ../../../../file/index.ndx -sep -o md$i-.gro 3;done
- # trr
- # 先搞个10step的测试下
- for i in {1..6};do echo 0|gmx_mpi trjconv -f ../../../md$i/md.trr -s ../../../md$i/md.tpr -n ../../../../file/index.ndx -o md$i-10step.trr -dump 0.02;done
- for a in {1..10};do mkdir repl$a;b=$((a*10));for i in {1..6};do cp sep/md$i-$b.gro ./repl$a;done;done
- ###"rerun.sh" 32L, 883C ######################################################################
- for a in {1..10}
- do
- for i in {1..6}
- do
- cd repl$a
- # pp
- echo 8|gmx_mpi trjconv -s ../../../md$i/md.tpr -f md$i*.gro -n ../../../../file/index.ndx -o md$i-pp.pdb
- echo 8|gmx_mpi convert-tpr -s ../../../md$i/md.tpr -n ../../../../file/index.ndx -o md$i-pp.tpr
- gmx_mpi mdrun -s md$i-pp.tpr -rerun md$i-pp.pdb
- mv ener.edr md$i-pp-ener.edr
- mv md.log md$i-pp.log
- mv traj.trr md$i-traj-pp.trr
- # ww
- echo 9|gmx_mpi trjconv -s ../../../md$i/md.tpr -f md$i*.gro -n ../../../../file/index.ndx -o md$i-ww.pdb
- echo 9|gmx_mpi convert-tpr -s ../../../md$i/md.tpr -n ../../../../file/index.ndx -o md$i-ww.tpr
- gmx_mpi mdrun -s md$i-ww.tpr -rerun md$i-ww.pdb
- mv ener.edr md$i-ww-ener.edr
- mv md.log md$i-ww.log
- mv traj.trr md$i-traj-ww.trr
- # sys
- gmx_mpi mdrun -s ../../../md$i/md.tpr -rerun md$i*.gro
- mv ener.edr md$i-sys-ener.edr
- mv md.log md$i-sys.log
- mv traj.trr md$i-traj-sys.trr
- cd ..
- done
- done
- #############################################################################################
- 85.24 /home/databank/zzy/project/MD/vsREMD-gpu/lywu-test-20241011/gro-extract/result
- for i in {2..6};do mkdir md$i;cp ../pbc/repl1/md$i-pp.log md$i/pbc-pp.log;cp ../pbc/repl1/md$i-ww.log md$i/pbc-ww.log;cp ../pbc/repl1/md$i.log md$i/pbc-sys.log;cp ../nopbc/repl1/md$i-sys.log md$i/nopbc-sys.log;cp ../nopbc/repl1/md$i-pp.log md$i/nopbc-pp.log;cp ../nopbc/repl1/md$i-ww.log md$i/nopbc-ww.log;cp ../../md$i/md.log md$i/vsREMD-cpu.log;done
- # 每一个能量项依次grep的,费时费力还容易出错
- # 这样看一下,跑10步,第一次的交换判断,是否进行周期性处理确实会有影响
- # 再试一下rms等其他周期性处理方法,看能不能拿到 rerun和vsREMD CPU版完全一致或更接近的结果
1012
- # md1 10step test
- echo 9|gmx_mpi trjconv -s ../../../md1/md.tpr -f ../../../md1/md.xtc -n ../../../../file/index.ndx -o ww-pbcmol.gro -dump 0.02 -pbc mol
- # trr 会显示没有盒子信息而报错
- echo 9|gmx_mpi convert-tpr -s ../../../md1/md.tpr -n ../../../../file/index.ndx -o ww.tpr
- gmx_mpi mdrun -s ../ww.tpr -rerun ../ww-pbcmol.gro
1023 debug
zjhan 脚本使用方法:
- # 更改setting里的 工作路径
- source ~/.gmx2022.5-remd.sh
- export CUDA_VISIBLE_DEVICES=0,1,2
- nohup python start.py &
还是老问题,nscale 为负值
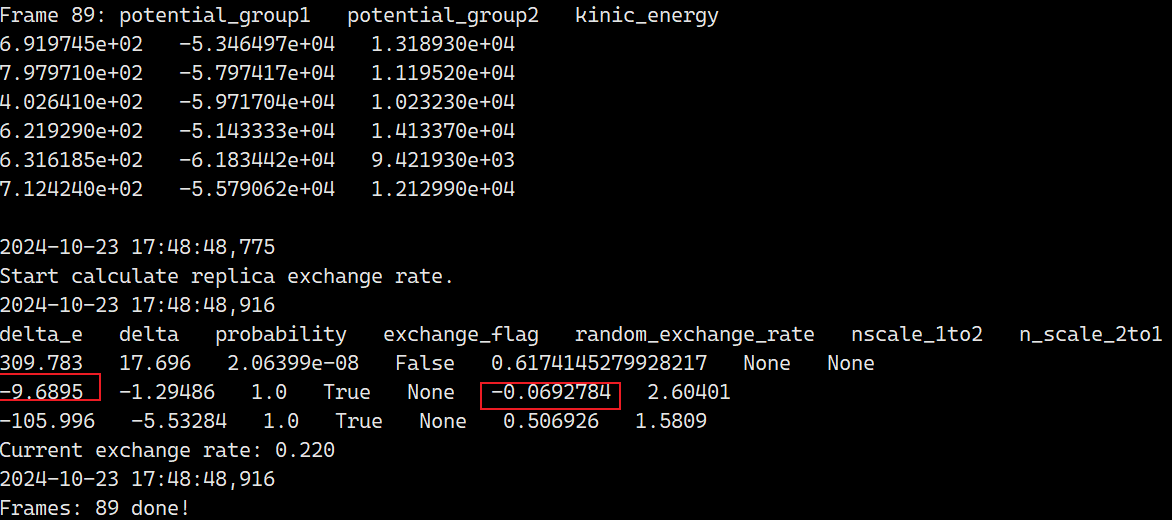
delta_e 是 potential_group1的差值,根据上面frame 89的potential_group1 输出结果,定位到负值nscale 的两个副本,减一下,果然是负值。
- tail 89/replica_*/log.log
- # 根据 log.log 里的 potential_group1定位到 两个副本文件夹
- 89/replica_2/log.log
- 89/replica_3/log.log
看了一下对应的gro,感觉可能还是 pbc 问题,晚上尝试修改pbc 代码(autoimage)
修改的地方:
- # setting.py
- # 1024 zyzhou
- CPPTRAJ_SH = f"{WORK_DIR}autoimage.sh"
- # MDRunner.py
- # 4090 autoimage版本(如上)测试
- (ljt) dddc@gpu-4090:/home/data/zzy/koff/vsREMD-gpu/test2-pbc$ nohup python start.py &
- [1] 1315074

除此以外,也交了平行任务
- (base) [chpeng@localhost test1]$ nohup python start.py &
- [1] 8979
- 1023 23:07 还在跑(狗头)
除此以外,还要尝试输出交换率,师兄算的时候没区分副本(地铁老人手机)
1024 debug
- # /home/chpeng/zzy/project/koff/vsREMD-gpu/zjhan-v0.1-1022-raw
test1:没区别
- # /home/chpeng/zzy/project/koff/vsREMD-gpu/zjhan-v0.1-1022-raw/89/replica_2/autoimage
- echo 0|gmx_mpi trjconv -s ../run.tpr -f ../run.gro -n ../../../index.ndx -o pbc-mol.pdb -pbc mol -ur compact
- sh autoimage.sh
- echo 8|gmx_mpi trjconv -s ../run.tpr -f pbc-mol-autoimage.pdb -n ../../../index.ndx -o 8.pdb
- echo 9|gmx_mpi trjconv -s ../run.tpr -f pbc-mol-autoimage.pdb -n ../../../index.ndx -o 9.pdb
- # 动能从run.log 里提取
- # 势能需要计算单点能
- echo 8|gmx_mpi convert-tpr -s ../run.tpr -n ../../../index.ndx -o 8.tpr
- gmx_mpi mdrun -s 8.tpr -rerun 8.pdb
- echo 9|gmx_mpi convert-tpr -s ../run.tpr -n ../../../index.ndx -o 9.tpr
- gmx_mpi mdrun -s 9.tpr -rerun 9.pdb
系统能量的合理性-run.log
目前的系统能量来源于 run.log 里的 “Statistics over 50001 steps using 501 frames”
而不是最后一帧,需要检查。
从 这个报错的副本看,如果用最后一帧,结果更差。
look-rerun-pdb
先尝试不同的周期性处理方法,并可视化为pdb 文件,确实是 pbcmolurcompact-auto 最好
- echo 8|gmx_mpi trjconv -s ../run.tpr -f ../run.xtc -n ../../../index.ndx -o pbcmolurcompact.pdb -pbc mol -ur compact
- sh autoimage.sh
- echo 8|gmx_mpi convert-tpr -s ../run.tpr -n ../../../index.ndx -o 8.tpr
- gmx_mpi mdrun -s 8.tpr -rerun pbcmolurcompact-auto.pdb
- mv md.log md-ww.log
- echo 9|gmx_mpi trjconv -s ../run.tpr -f ../run.xtc -n ../../../index.ndx -o pbcmolurcompact.pdb -pbc mol -ur compact
- sh autoimage.sh
- echo 9|gmx_mpi convert-tpr -s ../run.tpr -n ../../../index.ndx -o 9.tpr
- gmx_mpi mdrun -s 9.tpr -rerun pbcmolurcompact-auto.pdb
- mv md.log md-pp.log
- ######## "autoimage.sh" 6L, 113C ###############################################################
- cpptraj <<EOF
- parm pbcmolurcompact.pdb
- trajin pbcmolurcompact.pdb
- autoimage
- trajout pbcmolurcompact-auto.pdb
- EOF
- ################################################################################################
这样处理下来,得到的 ww,pp能量和之前略有不同(autoimage 一定要前面的构象做参考,所以需要输出全部轨迹)
最后,如果用本来的系统能量,可以是正值;用了最后一帧,就还是负值
look-rerun2-xtc
ww的结果不如 look-rerun-pdb
- echo 8|gmx_mpi trjconv -s ../run.tpr -f ../run.xtc -n ../../../index.ndx -o pbcmolurcompact.pdb -pbc mol -ur compact -dump 0
- echo 8|gmx_mpi trjconv -s ../run.tpr -f ../run.xtc -n ../../../index.ndx -o pbcmolurcompact.xtc -pbc mol -ur compact
- sh autoimage.sh
- echo 8|gmx_mpi convert-tpr -s ../run.tpr -n ../../../index.ndx -o 8.tpr
- gmx_mpi mdrun -s 8.tpr -rerun pbcmolurcompact-auto.xtc
- mv md.log md-ww.log
- echo 9|gmx_mpi trjconv -s ../run.tpr -f ../run.xtc -n ../../../index.ndx -o pbcmolurcompact.pdb -pbc mol -ur compact -dump 0
- echo 9|gmx_mpi trjconv -s ../run.tpr -f ../run.xtc -n ../../../index.ndx -o pbcmolurcompact.xtc -pbc mol -ur compact
- sh autoimage.sh
- echo 9|gmx_mpi convert-tpr -s ../run.tpr -n ../../../index.ndx -o 9.tpr
- gmx_mpi mdrun -s 9.tpr -rerun pbcmolurcompact-auto.xtc
- mv md.log md-pp.log
- ######## "autoimage.sh" 6L, 113C ###############################################################
- cpptraj <<EOF
- parm pbcmolurcompact.pdb
- trajin pbcmolurcompact.pdb
- autoimage
- trajout pbcmolurcompact-auto.pdb
- EOF
- ################################################################################################
这样处理下来,得到的 ww,pp能量和之前略有不同(autoimage 一定要前面的构象做参考)
1025 debug
85.9 /home/chpeng/zzy/project/koff/vsREMD-gpu/zjhan-v0.1-1022-raw/look
- for i in {0..5};do echo 0|gmx_mpi trjconv -s ../89/replica_${i}/run.tpr -f ../replica_${i}.xtc -o ${i}-pbcmolurcompact.pdb -pbc mol -ur compact -skip 100;done
与师姐讨论,突然发现:
最低温和最高温就不该交换。。。。
- # 4090上交一个5个副本的测试
- (ljt) dddc@gpu-4090:/home/data/zzy/koff/vsREMD-gpu/test3-5replica$ nohup python start.py &
- [1] 2074415
1104 温度连续轨迹的获取
- # 172.21.75.1 /home/data/zzy/koff/vsREMD-gpu/replica_temp
- # gmx 命令
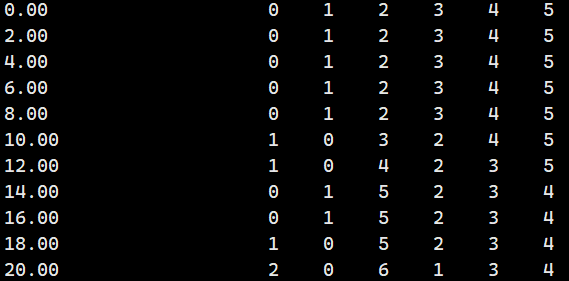
- gmx_mpi trjcat -f replica_0.xtc replica_1.xtc replica_2.xtc replica_3.xtc replica_4.xtc replica_5.xtc -demux test.xvg
- # 其中 replica_0.xtc - replica_5.xtc 就是 vsREMD-gpu-1.0 输出的原始轨迹,replica_index.xvg需要由temperature.txt 经过文本操作而得
- # 我们需要 replica_temp.xvg 的内容形式如下
- # 第一列是时间,单位ps
- # 第25列(第x个副本的记录终止于5x+20列) 开始是温度index,0对应第一个温度,以此类推
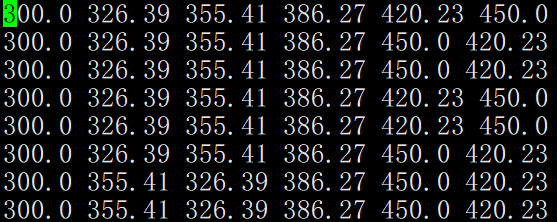
- # 目前的 temperature.txt 是这样
- # shell 文本操作
- sed 's/300.0/0 /g' temperature.txt|sed 's/326.39/1 /g'|sed 's/355.41/2 /g'|sed 's/386.27/3 /g'|sed 's/420.23/4 /g'|sed 's/450.0/5 /g' > sed.xvg
- awk '{ printf "%-24s%s\n", sprintf("%.2f", 100.00 * (NR - 1)), $0 }' sed.xvg > test.xvg
- # 拼接
- gmx_mpi trjcat -f replica_0.xtc replica_1.xtc replica_2.xtc replica_3.xtc replica_4.xtc replica_5.xtc -demux test.xvg
- # 生成tpr,去水+周期性处理
- for a in {0..5};do b=$((a + 1));c=
`sed -n "${b}p" temp`;sed "s/+++/$c/g" run_template.mdp >md${a}.mdp;gmx_mpi grompp -f md${a}.mdp -c ../0/replica_${a}/run.gro -p ../top.top -n ../index.ndx -o md${a}.tpr -maxwarn 1;echo 9|gmx_mpi trjconv -s md${a}.tpr -f ../replica_${a}.xtc -n ../index.ndx -o skip50-${a}.xtc -skip 50 -pbc mol -ur compact;done - # 拼接温度连续轨迹
- gmx_mpi trjcat -f skip50-0.xtc skip50-1.xtc skip50-2.xtc skip50-3.xtc skip50-4.xtc skip50-5.xtc -demux test.xvg
- # 生成参考文件 dry.pdb
- gmx_mpi trjconv -s md0.tpr -f ../replica_0.xtc -n ../index.ndx -o dry.pdb -dump 0 -pbc mol -ur compact