
MD GPU speed test
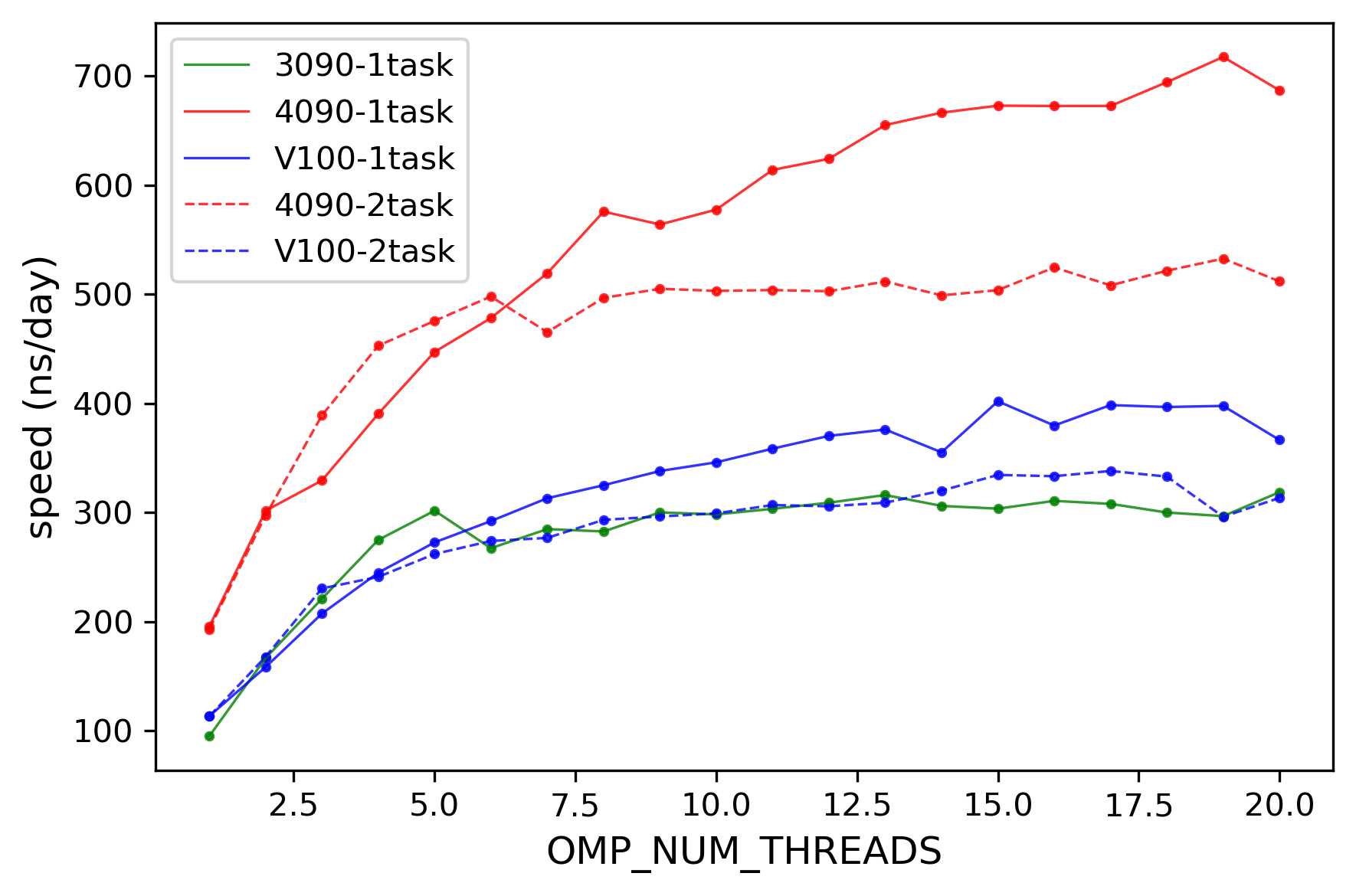
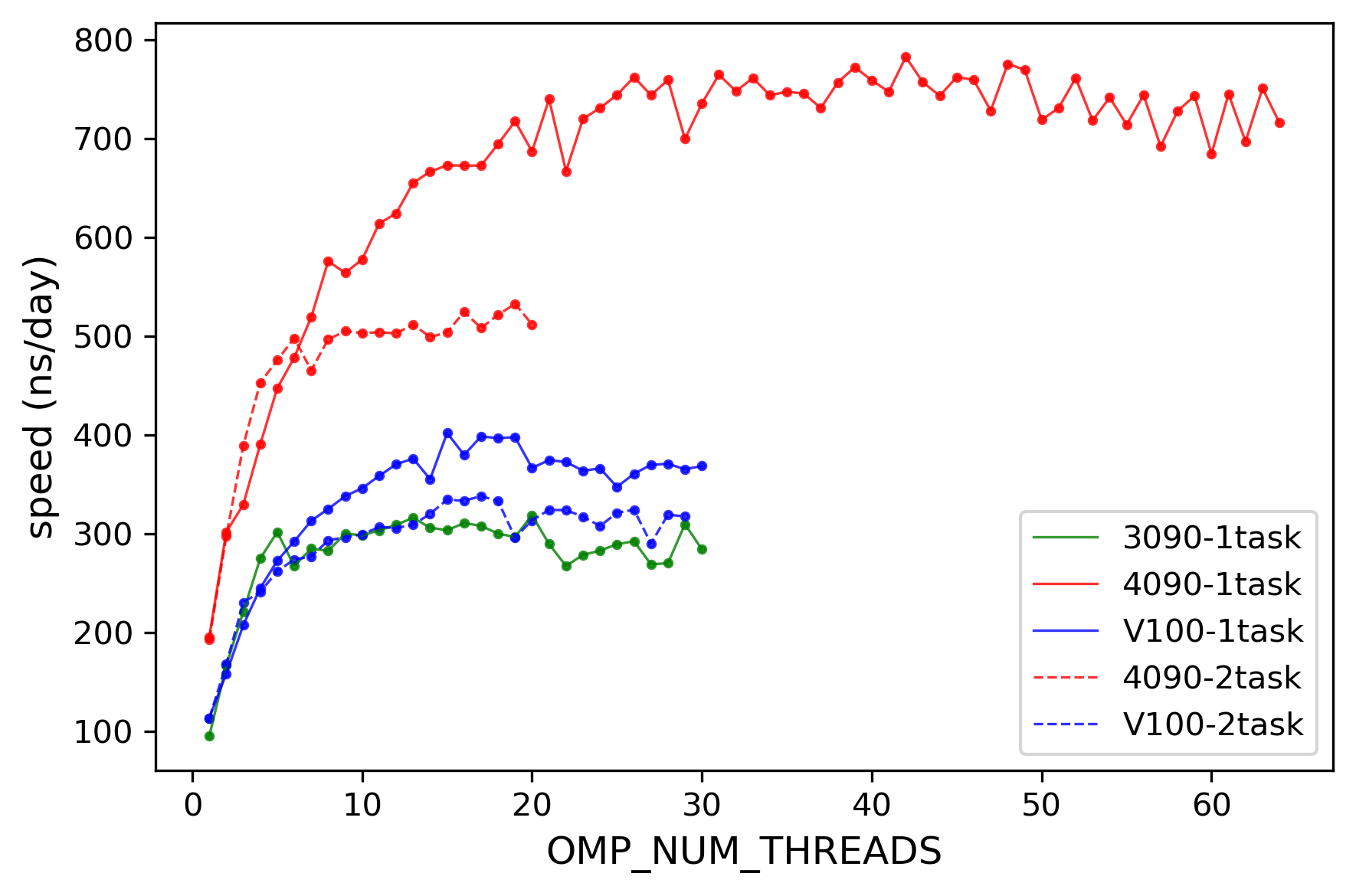
2024-05-15 不同GPU性能比较
- # 测试了组内目前有的3090,v100,4090的性能,测试了单任务/多任务情况下的性能
- 结论:对于 CMD任务 4090>v100≈3090
- 2025-1-14:实际上,gmx安装编译时用的指令集会对软件性能造成影响
- 4090 172.21.75.1
- /home/dddc/zzy/test/0515-gmx/single-gpu-Multitasking
- /home/dddc/zzy/test/0515-gmx/test-OMP_NUM_THREADS
- 3090
- /home/dddc/zzy/people/lywu/20240516-test-OMP_NUM_THREADS
- v100 172.21.86.9
- /home/chpeng/zzy/md/v100-1task
- /home/chpeng/zzy/md/v100-2task

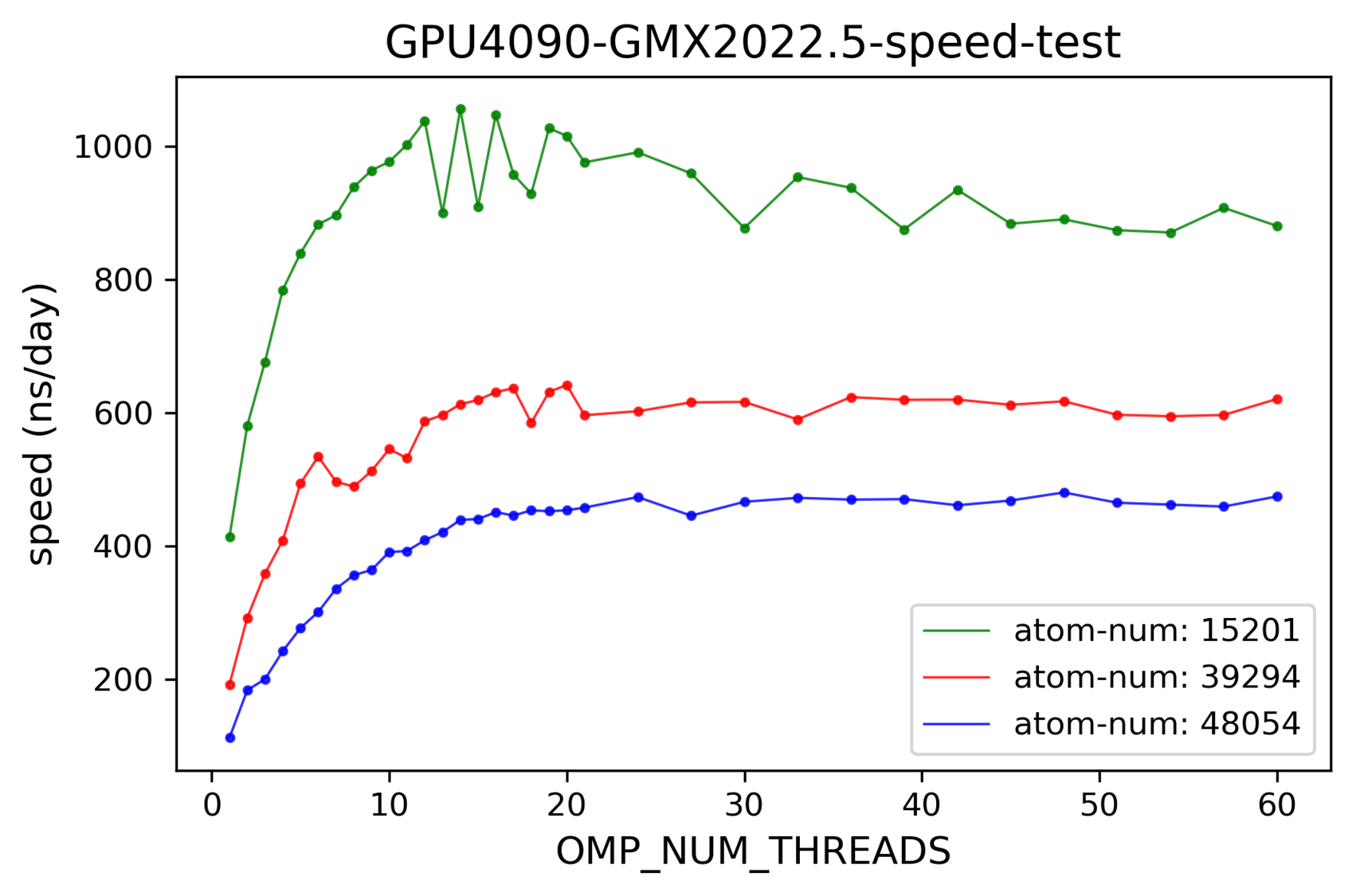
2024-11-05 体系大小的影响
与预期一致,体系越大模拟速度越慢。
- # 172.21.75.1 /home/data/zzy/test/gpu-speed-test/20241104/
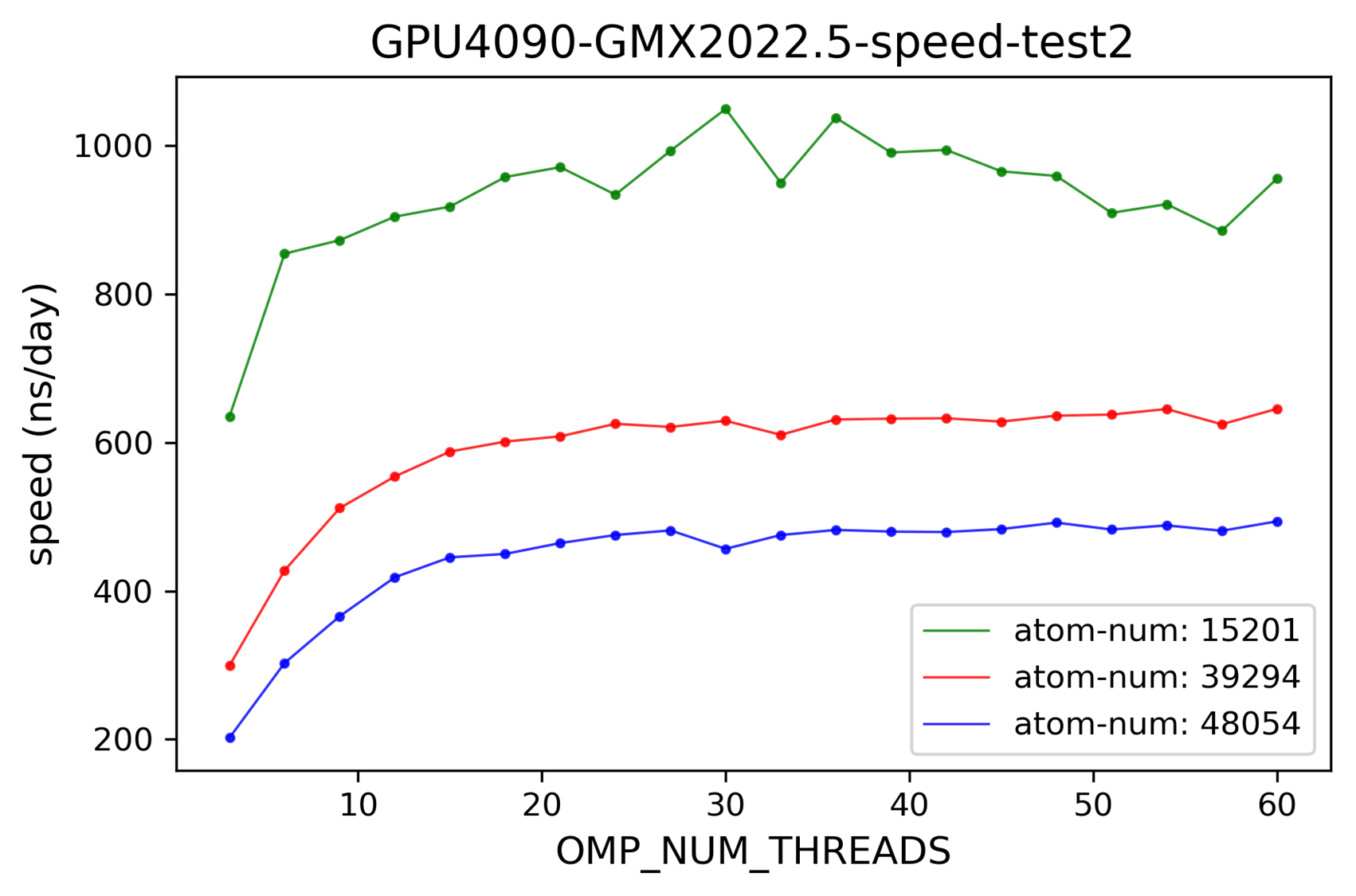
- # 11.5 20:22 已准备好大体系的test.tpr
- # 4090 目前无空余cpu,明天测试
/home/data/zzy/test/gpu-speed-test/20241104/sys/577914-7k4n-trimer-wt/test.tpr
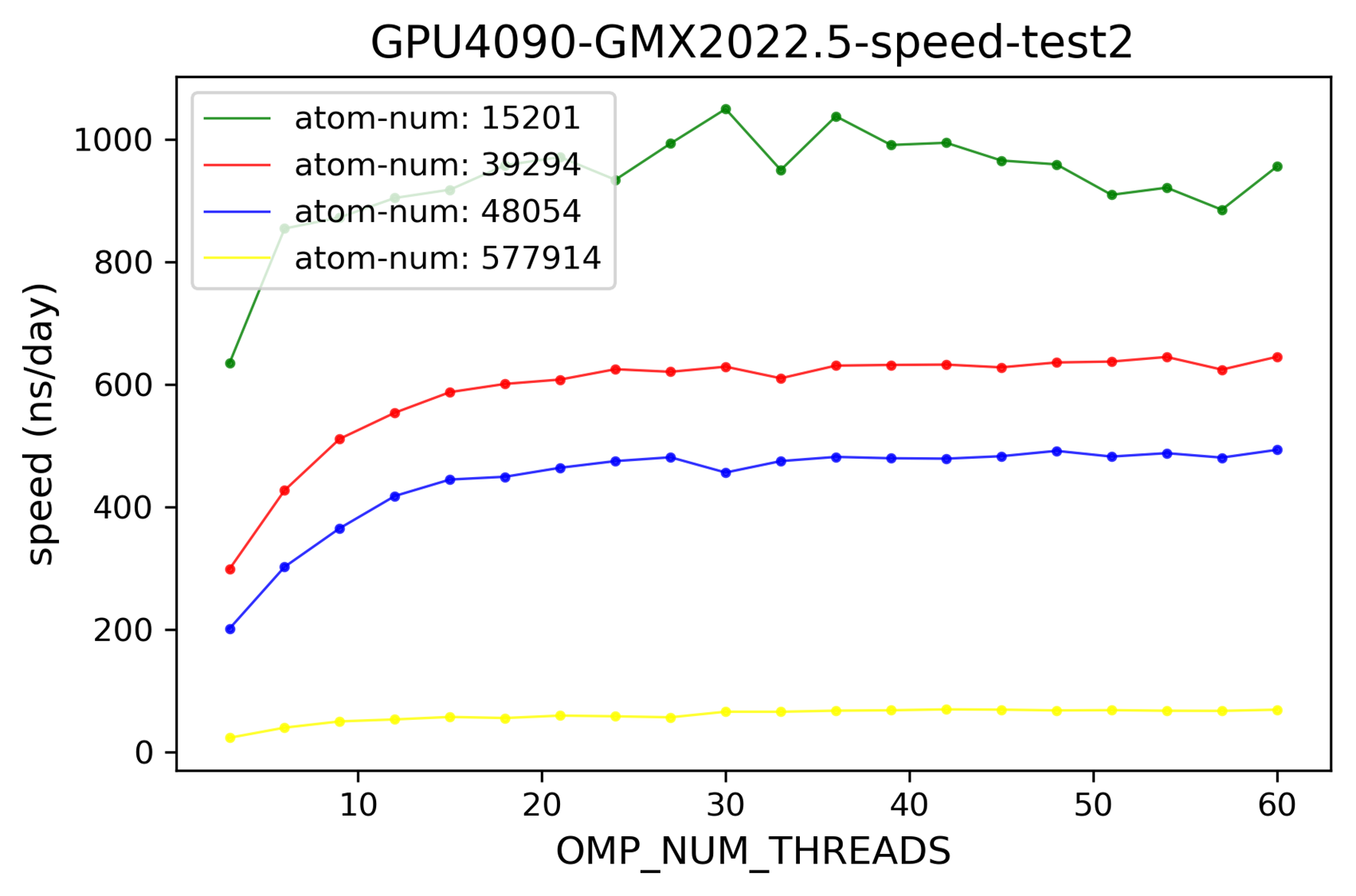
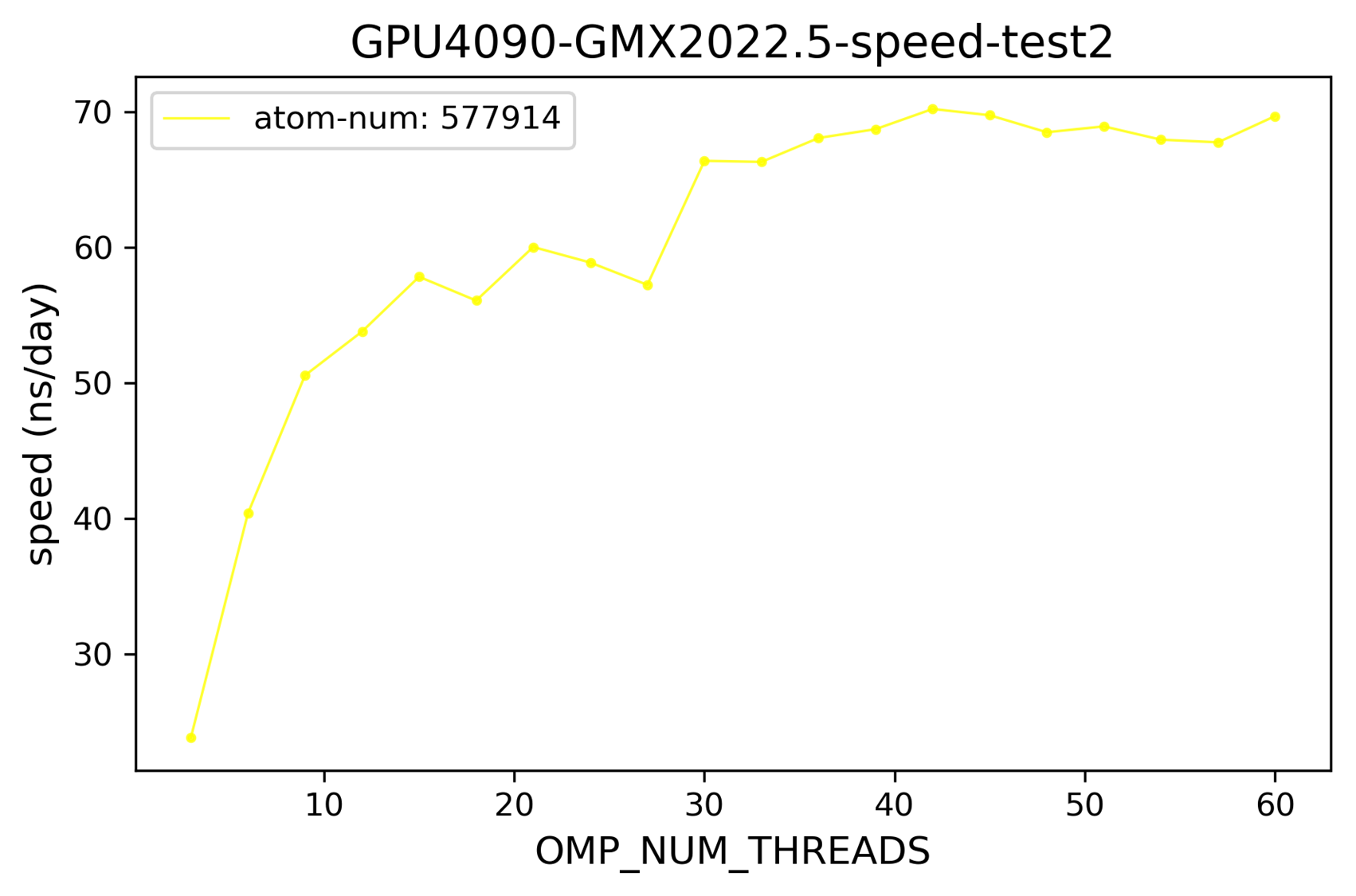
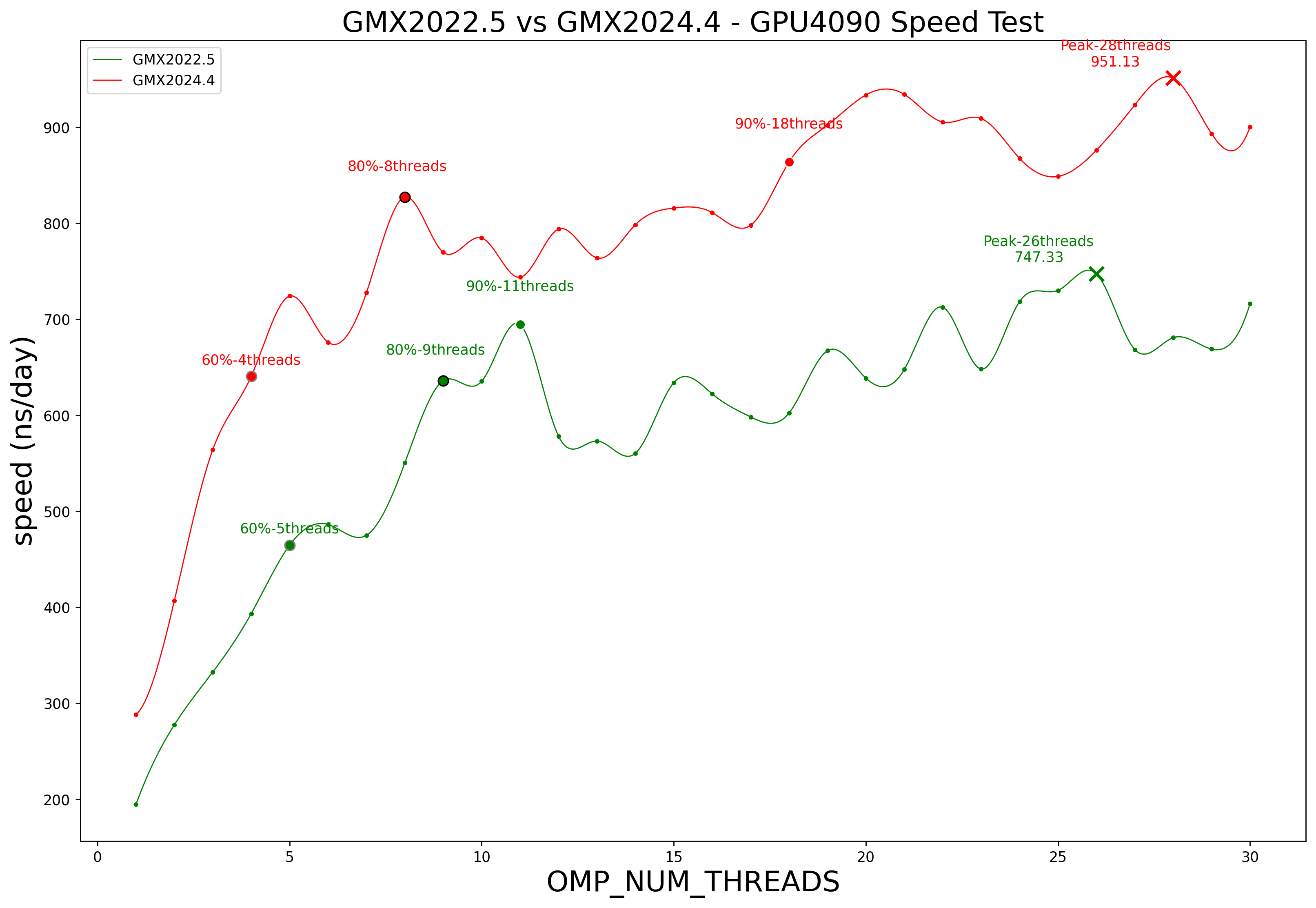
2025-01-14 不同gmx版本的影响
- # v100 /home/chpeng/zzy/project/koff/md/GPU-speed-test/gmx-2024.4_compare_2022.5
- # 在 85.9(v100)服务器 1,2盘 上同步测试gmx2022.5 gmx2024.4的速度,线程数1-30
- # 初步看下来2024比2022快较多,为确保无错,可以交换GPU再测试一次,结果更严谨
- # 可视化位置1:4090 /home/data/zzy/test/gpu-speed-test/
- # !!!! v100 的物理 cpu核数有限,不支持同时两个任务跑高线程测试,要注意!
- # 17:56 GPU2正在跑 GMX2022 1-30线程测试
- # 等吃完回来,看一下 GMX2022 在GPU2,GPU1上速度有无差别,如果基本一致,则等2022的任务跑的差不多提交2024的新一轮测试,可以过夜
- # 数据清洗和可视化的脚本已部署完成,测试结果一拿到就可以分析
2025-01-15 amb24测速
- export PATH=/home/data/zzy/software/amber_bin/bin:$PATH
- # 2025-1-15 等待师姐把amber输出文件发过来
- 4090 /home/data/zzy/test/gpu-speed-test/gmx-2024.4_compare_2022.5/amber24/lywu-zzy-get-apo
- #################### "cpptraj.log" 6L, 146B #######################################
- # 01/16/25 02:29:48 (实际时间 10:24)
- parm ../lywu/complex.prmtop
- trajin ../lywu/complex.inpcrd
- strip :MOL outprefix noMOL
- trajout noMOL.complex.inpcrd restart
- run
- ###################################################################################
- # cpptraj 得到去除配体的amber参数文件(noMOL.complex.inpcrd noMOL.complex.prmtop)
- # 补充说明
- 1. outprefix 参数加上后自动输出拓扑文件
- 2. restart 后指定 输出坐标文件 Coordinate/restart file specification (inpcrd, restrt)
- # amber 预平衡
- # 4090 /home/data/zzy/test/gpu-speed-test/gmx-2024.4_compare_2022.5/amber24/pre-bal
- cp /home/data/zzy/people/xcy/jawang-amber24-check/test2/*in ./
- cp ../lywu-zzy-get-apo/noMOL.complex.* ./
- export PATH=/home/data/zzy/software/amber_bin/bin:$PATH
- nohup bash run-cmd.sh & (注释掉05-cmd)
- # amber 测速
- #4090 /home/data/zzy/test/gpu-speed-test/gmx-2024.4_compare_2022.5/amber24/speed-test
- nohup bash run-cmd.sh &(注释掉除05-cmd以外的行)
- # 测试思路:
- 1. 单GPU,双GPU测试(进程数与GPU数目一致);
- 2. 模拟引擎测试(pmemd.cuda /pmemd.cuda.MPI /pmemd.cuda_SPFP /pmemd.cuda_DPFP.MPI)
- https://computecanada.github.io/molmodsim-amber-md-lesson/13-Running_Simulations/index.html
- # 任务记录
- /home/data/zzy/test/gpu-speed-test/gmx-2024.4_compare_2022.5/amber24/speed-test/
- dddc@gpu-4090:/home/data/zzy/test/gpu-speed-test/gmx-2024.4_compare_2022.5/amber24/speed-test/pmemd.cuda$ nohup bash run-cmd.sh &
- [1] 3698286
- dddc@gpu-4090:/home/data/zzy/test/gpu-speed-test/gmx-2024.4_compare_2022.5/amber24/speed-test/pmemd.cuda_SPFP$ nohup bash run-cmd.sh &
- [2] 3698330
- dddc@gpu-4090:/home/data/zzy/test/gpu-speed-test/gmx-2024.4_compare_2022.5/amber24/speed-test/pmemd.cuda_DPFP$ nohup bash run-cmd.sh &
- [3] 3698371
- nohup mpirun -np 2 /home/data/zzy/software/amber_bin/bin/pmemd.cuda.MPI -O -i 05-cmd.in -p noMOL.complex.prmtop -c 04-npt.rst -o 05-cmd.out -x 05-cmd.nc -r 05-cmd.rst &
- nohup mpirun -np 2 /home/data/zzy/software/amber_bin/bin/pmemd.cuda_SPFP.MPI -O -i 05-cmd.in -p noMOL.complex.prmtop -c 04-npt.rst -o 05-cmd.out -x 05-cmd.nc -r 05-cmd.rst &
- nohup mpirun -np 2 /home/data/zzy/software/amber_bin/bin/pmemd.cuda_DPFP.MPI -O -i 05-cmd.in -p noMOL.complex.prmtop -c 04-npt.rst -o 05-cmd.out -x 05-cmd.nc -r 05-cmd.rst &
- 2025-1-18 可视化位置
- 4090 /home/data/zzy/test/gpu-speed-test/
2025-5-9 GMX2024 GPU并行
- 75.2 /home/data/zzy/koff/gmx-test/2-4090-one-md
- # 使用是48054个原子的Hiv-1体系
- cp ../sys/48054-hiv-1-a047/* ./
- # GMX 编译时-DGMX_MPI=on的话,会编译为MPI版本,该版本下可以通过mpirun -np X 设置进程数(独立进程)
- # MPI版本中调用GPU并行只能用mpirun来实现,线程数通过 export OMP_NUM_THREADS=20 来调整
- # 4090的测试结果,-np 2 线程数居然上不去,—np 3/4 就可以达到 OMP_NUM_THREADS设置的值
- # 这个mdrun调用的总线程数是 -np 和 OMP_NUM_THREADS 的乘积
- # GPU 并行时,PME需要指定分配给GPU,且一定需要 -npme 指定rank(在这里即为进程),相比于不设置,速度会有明显提升
- # -npme 的设置需要考虑 PP/PME负载的平衡,使其达到更好的速度
- export OMP_NUM_THREADS=20
- export CUDA_VISIBLE_DEVICES=0,1,2,3
- gmx_mpi mdrun -v -deffnm test
- # 1块GPU 20线程 1个shell进程
- # 速度为 411 ns/day 左右
- mpirun -np 2 gmx_mpi mdrun -v -deffnm test
- # 2块GPU 实际只调用了4个线程左右(2*2)2个shell进程
- # 速度极慢(短时间内停止都测不出来速度)
- mpirun -np 2 gmx_mpi mdrun -pme gpu -npme 1 -v -deffnm test
- # 2块GPU 实际只调用了3个线程左右(PME看起来是1个线程,PP是两个)2个shell进程
- # 速度为 39 ns/day 左右
- mpirun -np 3 gmx_mpi mdrun -v -deffnm test
- # 3块GPU 60线程(20*3) 3个shell进程
- # 速度为 84 ns/day 左右
- mpirun -np 3 gmx_mpi mdrun -pme gpu -npme 1 -v -deffnm test
- # 3块GPU 41线程(PME看起来是1个线程,PP是每个进程20个) 3个shell进程
- # 速度为 135 ns/day 左右
- mpirun -np 4 gmx_mpi mdrun -v -deffnm test
- # 4块GPU 80线程(20*4) 4个shell进程
- # 速度为 88 ns/day 左右
- mpirun -np 4 gmx_mpi mdrun -pme gpu -npme 1 -v -deffnm test
- # 4块GPU 61线程(PME看起来是1个线程,PP是每个进程20个) 4个shell进程
- # 速度为 182 ns/day 左右
- # GMX 编译时不加-DGMX_MPI=on的话,可执行文件就是gmx而不是gmx_mpi了
- 已在4090上编译完成非MPI版本
- export PATH=/home/data/zzy/software/gmx2024/nompi/gromacs-2024.4/install/bin/:$PATH
- export LD_LIBRARA_PATH=/home/data/zzy/software/gmx2024/nompi/gromacs-2024.4/install/lib:${LD_LIBRARY_PATH}
- # 这个版本下,可通过内部thread-mpi即 -ntmpi 并行(rank级别并行),进程不是独立的,会在一个shell 进程下,这个进程调用的总线程数是 -ntmpi 和 OMP_NUM_THREADS 的乘积。这里OMP_NUM_THREADS和-ntomp需要是一样的,不一样的话会报错
- # 非MPI的gmx一定要指定 -ntmpi,-ntmpi若大于1,会自动在多个GPU上并行(同一个shell 进程)
- export OMP_NUM_THREADS=20
- gmx mdrun -ntmpi 1 -v -deffnm test
- # 速度为 414 ns/day 左右
- gmx mdrun -ntmpi 2 -v -deffnm test
- # 速度为 72 ns/day 左右
- gmx mdrun -ntmpi 2 -pme gpu -npme 1 -v -deffnm test
- # 速度为 297 ns/day 左右
- gmx mdrun -ntmpi 3 -v -deffnm test
- # 速度为 106 ns/day 左右
- gmx mdrun -ntmpi 3 -pme gpu -npme 1 -v -deffnm test
- # 速度为 303 ns/day 左右
需要测试大体系的速度,看看是否是目前的体系太小,不值得GPU并行导致的速度下降
- 4090 /home/data/zzy/koff/gmx-test/2-4090-one-md/577914-7k4n-trimer-wt/gmx_mpi
- export OMP_NUM_THREADS=25
- export CUDA_VISIBLE_DEVICES=0,1,2,3
- mkdir np1 mp2 np2_pme np3 np3_pme np4 np4_pme
- gmx_mpi mdrun -v -deffnm test
- # 1块GPU 20线程 1个shell进程
- # 速度为 411 ns/day 左右
- mpirun -np 2 gmx_mpi mdrun -v -deffnm test
- # 2块GPU 实际只调用了4个线程左右(2*2)2个shell进程
- # 速度极慢(短时间内停止都测不出来速度)
- mpirun -np 2 gmx_mpi mdrun -pme gpu -npme 1 -v -deffnm test
- # 2块GPU 实际只调用了3个线程左右(PME看起来是1个线程,PP是两个)2个shell进程
- # 速度为 39 ns/day 左右
- mpirun -np 3 gmx_mpi mdrun -v -deffnm test
- # 3块GPU 60线程(20*3) 3个shell进程
- # 速度为 84 ns/day 左右
- mpirun -np 3 gmx_mpi mdrun -pme gpu -npme 1 -v -deffnm test
- # 3块GPU 41线程(PME看起来是1个线程,PP是每个进程20个) 3个shell进程
- # 速度为 135 ns/day 左右
- mpirun -np 4 gmx_mpi mdrun -v -deffnm test
- # 4块GPU 80线程(20*4) 4个shell进程
- # 速度为 88 ns/day 左右
- mpirun -np 4 gmx_mpi mdrun -pme gpu -npme 1 -v -deffnm test
参考资料: